
The vault or more precisely the “Identity Vault” is a single pane view of all the collated data of your users, from the various data source repositories. This sounds like a lot of jargon but it’s quite simple really.
In the diagram below we look at a really simple attribute firstName (givenName within AD) 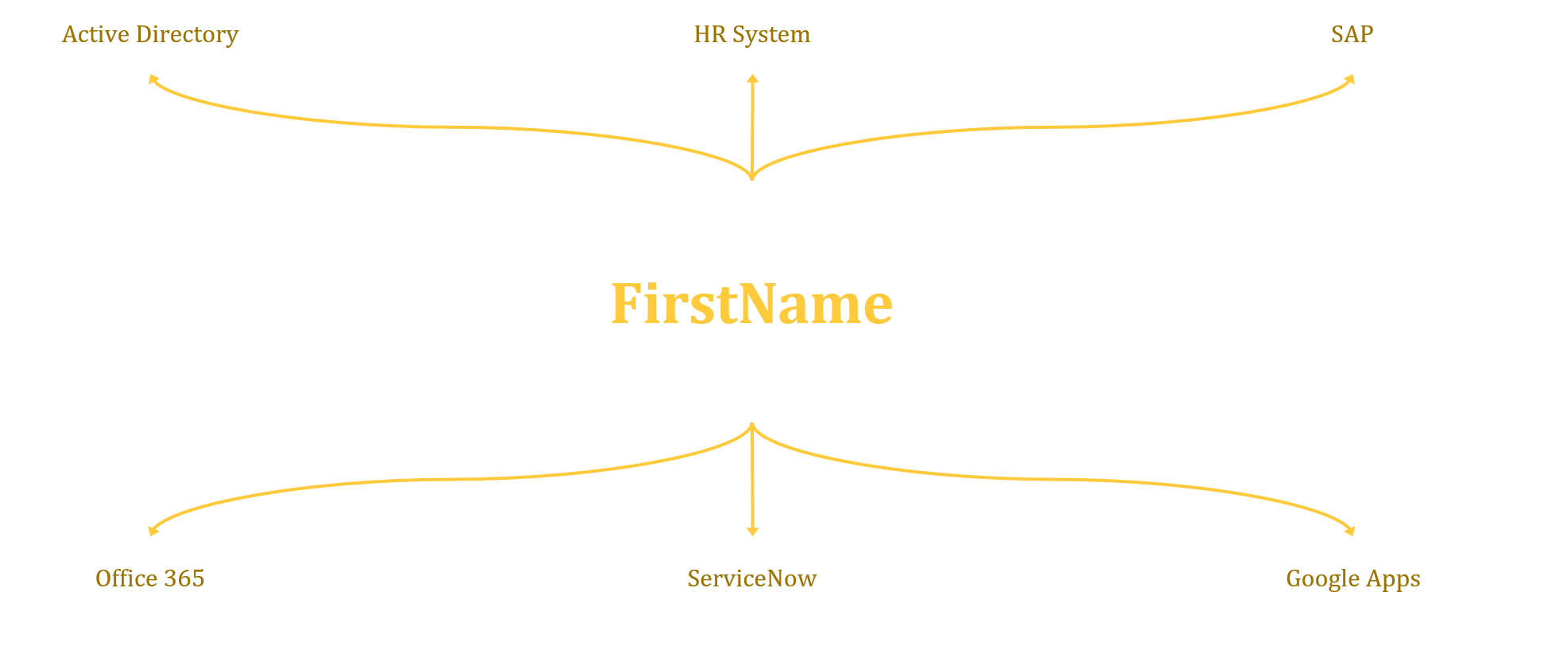
As you will see at the centre is the attribute, and branching off this is all the Connected Systems, i.e. Active Directory. What this doesn’t illustrate very well is the specific data flow, where this data is coming from and where it’s going to. This comes down to import and export rules as well as any precedence rules that you need to put in place.
The Identity Vault, or Central Data Repository, provides a central store of an Identities information aggregated from a number of sources. It’s also able to identify the data that exists within each of the connected systems from which it either collects the identity information from or provides the information to as a target system. Sounds pretty simple right?
Further to all the basics described above, each object in the Vault has a Unique Identifier, or an Anchor. This is a unique value that is automatically generated when the user is created to ensure that regardless of what happens to the users details throughout the lifecycle of the user object, we are able to track the user and update changes accordingly. This is particularly useful when you have multiple users with the same name for example, it avoids the wrong person being updated when changes occur.
| Attribute | User 1 | User 2 |
| FirstName | John | John |
| LastName | Smith | Smith |
| Department | Sales | Sales |
| UniqueGUID | 10294132 | 18274932 |
So the table above provides the most simplest forms of a users identity profile, whereas a complete users identity profile will consist of many more attributes, some of which maybe custom attributes for specific purposes, as in the example demonstrated below;
| Attribute | ContributingMA | Value |
| AADAccountEnabled | AzureAD Users | TRUE |
| AADObjectID | AzureAD Users | 316109a6-7178-4ba5-b87a-24344ce1a145 |
| accountName | MIM Service | jsmith |
| cn | PROD CORP AD | Joe Smith |
| company | PROD CORP AD | Contoso Corp |
| csObjectID | AzureAD Users | 316109a6-7178-4ba5-b87a-24344ce1a145 |
| displayName | MIM Service | Joe Smith |
| domain | PROD CORP AD | CORP |
| EXOPhoto | Exchange Online Photos | System.Byte[] |
| EXOPhotoChecksum | Exchange Online Photos | 617E9052042E2F77D18FEFF3CE0D09DC621764EC8487B3517CCA778031E03CEF |
| firstName | PROD CORP AD | Joe |
| fullName | PROD CORP AD | Joe Smith |
| PROD CORP AD | joe.smith@contoso.com.au | |
| mailNickname | PROD CORP AD | jsmith |
| o365AccountEnabled | Office365 Licensing | TRUE |
| o365AssignedLicenses | Office365 Licensing | 6fd2c87f-b296-42f0-b197-1e91e994b900 |
| o365AssignedPlans | Deskless, MicrosoftCommunicationsOnline, MicrosoftOffice, PowerAppsService, ProcessSimple, ProjectWorkManagement, RMSOnline, SharePoint, Sway, TeamspaceAPI, YammerEnterprise, exchange | |
| o365ProvisionedPlans | MicrosoftCommunicationsOnline, SharePoint, exchange | |
| objectSid | PROD CORP AD | AQUAAAAAAAUVAAAA86Yu54D8Hn5pvugHOA0CAA== |
| sn | PROD CORP AD | Smith |
| source | PROD CORP AD | WorkDay |
| userAccountControl | PROD CORP AD | 512 |
| userPrincipalName | PROD CORP AD | jsmith@contoso.com.au |
So now we have more complete picture of the data, where it’s come from and how we connect that data to a users’ identity profile. We can start to look at how we synchronise that data to any and all Managed targets. It’s very important to control this flow though, to do so we need to have in place strict governance controls about what data is to be distributed throughout the environment.
One practical approach to managing this is by using a data exchange agreement. This helps the organisation have a more defined understanding of what data is being used by what application and for what purpose, it also helps define a strict control on what the application owners can do with the data being consumed for example, strictly prohibiting the application owners from sharing that data with anyone, without the written consent of the data owners.
In my next post we will start to discuss how we then manage target systems, how we use the data we have to provision services and manage the user information through what’s referred to as synchronisation rules.
As with all my posts if, you have any questions please drop me a note.