Azure Bastion’s current annoying limitation
Originally posted on here at https://lucian.blog. Follow Lucian on Twitter @lucianfrango.
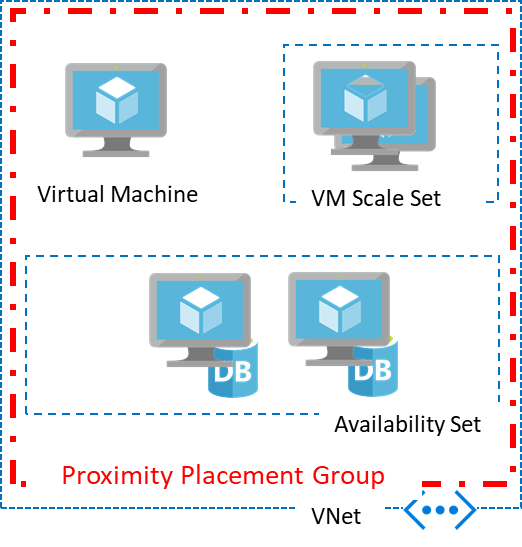
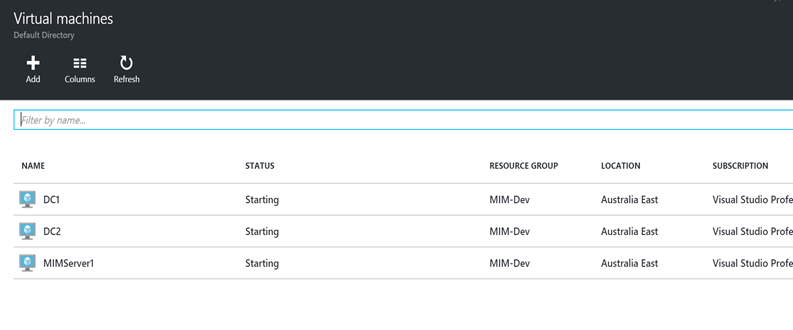
Since this service stumbled on the open web by way of a leak in June 2019 and having used it for a while now in preview plus since its been GA- for me this seems to be the best way to conduct secure remote access to IaaS infrastructure in Azure.
The idea of not having to deploy any internet accessible infrastructure (not having to open up TCP22 or TCP3389) to the avalanche of 1337 h4x0rs trying to gain access to anything and everything on those ports is great news.