Nested Virtual PowerShell Desktop Environments on Windows 10 & Windows Server 2019 in Azure – Part 3
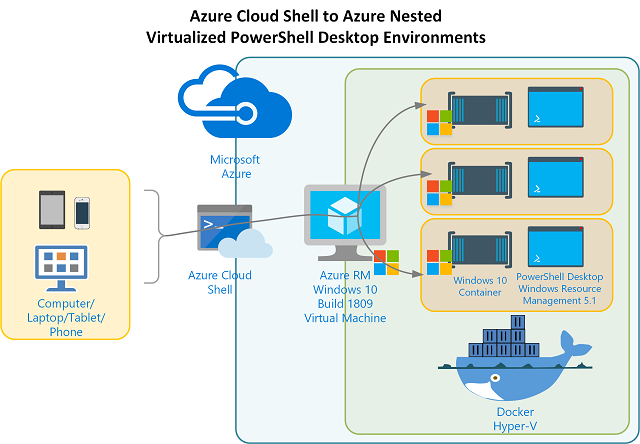
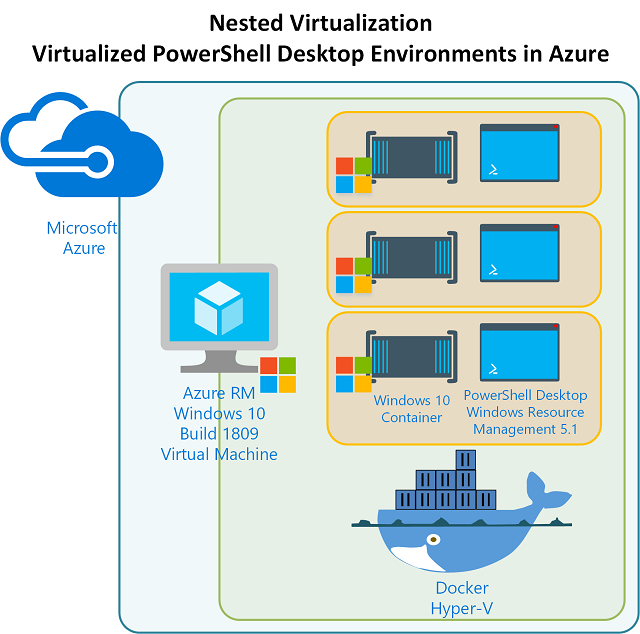
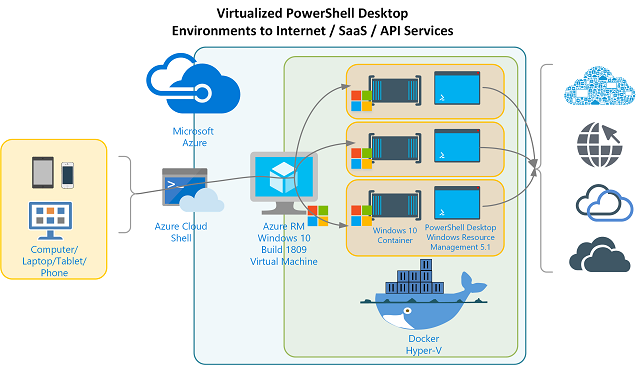
This is the third and likely last post in this series. In Part 1 I introduced the capability to have Virtual PowerShell Environments using Docker and the full Windows 10 / Server 2019 Build 1809 container images. In Part 2 I detailed remotely access the Azure RM Windows 10 / Server 2019 host that contains the Docker Container with our full Windows 1809 environment (and therefore PowerShell Desktop).
In this post I’ll detail building a Docker Image based off of the Windows 1809 Container image.… [Keep reading] “Nested Virtual PowerShell Desktop Environments on Windows 10 & Windows Server 2019 in Azure – Part 3”