In a recent project, we had a requirement to prevent specific selective content from shared externally while still allowing the flexibility of external sharing for all users. We were able to make it possible through Security and Compliance Center. There are few ways to achieve this, Auto-classify (see below conclusion section for more info), Selective apply via Labels and both.
Note: Till recently (Dec 2018), there was a bug in Office 365 which was preventing this DLP policy with Labels to work. This is fixed in the latest release so available for use.
In this blog, we will look at the process where business users can decide the content to be shared externally or not. This is a nifty feature, because there are cases when the content could be classified as secured even when they don’t have any sensitive info such as contracts (without business info) or invoices (with only business name). Also, there are cases when content could be public even when the document has sensitive info because the company has decided to make it public. So, at the end it is up to the discretion of the owner to decide the content’s privacy and hence this feature a great value in these scenarios.
Note: If you would like to auto classify the content using Sensitive info types, please refer to the great article
here. This process leverages the machine learning capabilities of Office 365 engine to identify secure content and automatically apply the security policy on it.
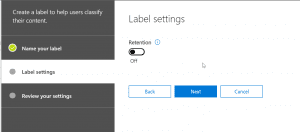
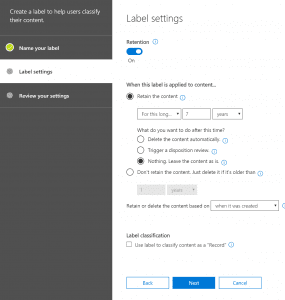
The first step is to create a Retention label (somehow this doesn’t work with Security labels, so must create retention label). After creating a label, publish the label to the selected locations, for our use case we will post it to SharePoint Sites only. While the label is published, we could go ahead and create a DLP policy to prevent sharing with external users (I was not able to make it work while set to Test with notification so put it to on state to test also). After this, when you apply the label to a document, after some time (takes about 1-2 min to affect), then the content is not able to be shared with external users. Lets’ look at each of the above steps in detail below.
Steps:
- First step is to create a retention label in Security and Compliance center. To my astonishment, the selective process doesn’t work with Security Labels but Retention Labels, so will create Retention Labels. If it is optional to apply a retention period to the content, then the retention period can be left, so not required for this exercise.
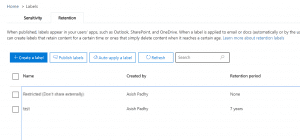
- Secondly, we will publish the label to SharePoint Sites, for our requirement. I haven’t tried the process with other sources such as Outlook and One Drive but should work the same when applied.
Note: It takes about a day for the retention labels to publish to SharePoint sites, so please wait for that to become available. We can move to the next configuration step right away but will have to wait for the label to be published to stop sharing.
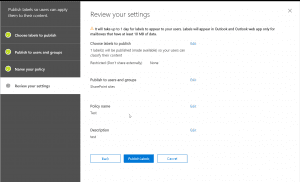
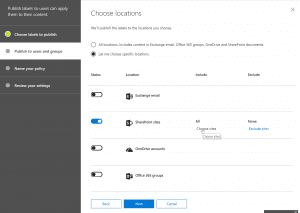
- Next, we could create a DLP policy for the content to be applied. For creating a DLP policy we need to follow the below configuration steps. Once created, we might have to turn it on in order to test it.
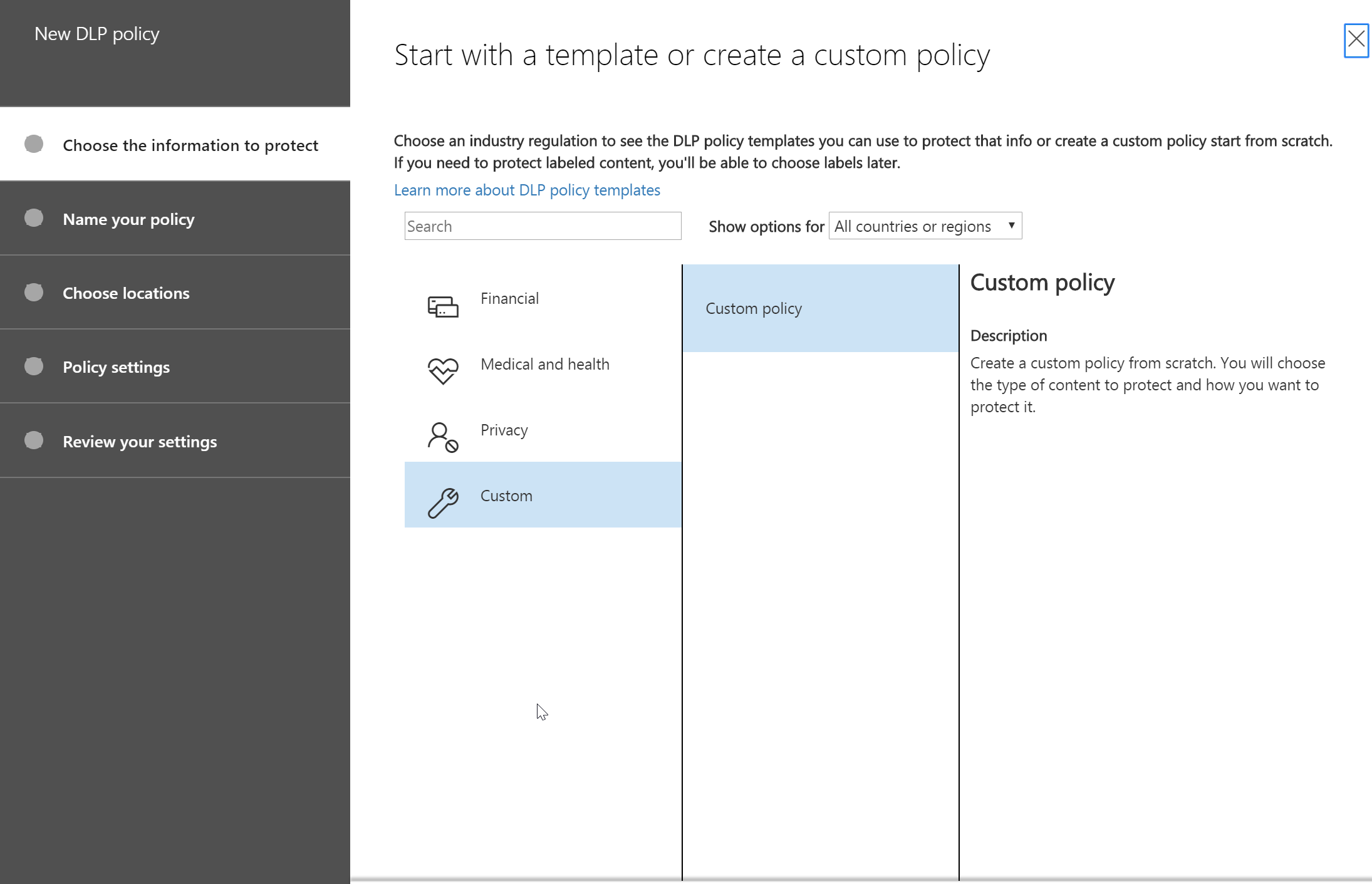
- First step of the policy creation would be select Custom Policy for DLP policy creation and give it a name.
- Then, we would select the sources to be included for this policy. In our case, it is only SharePoint.
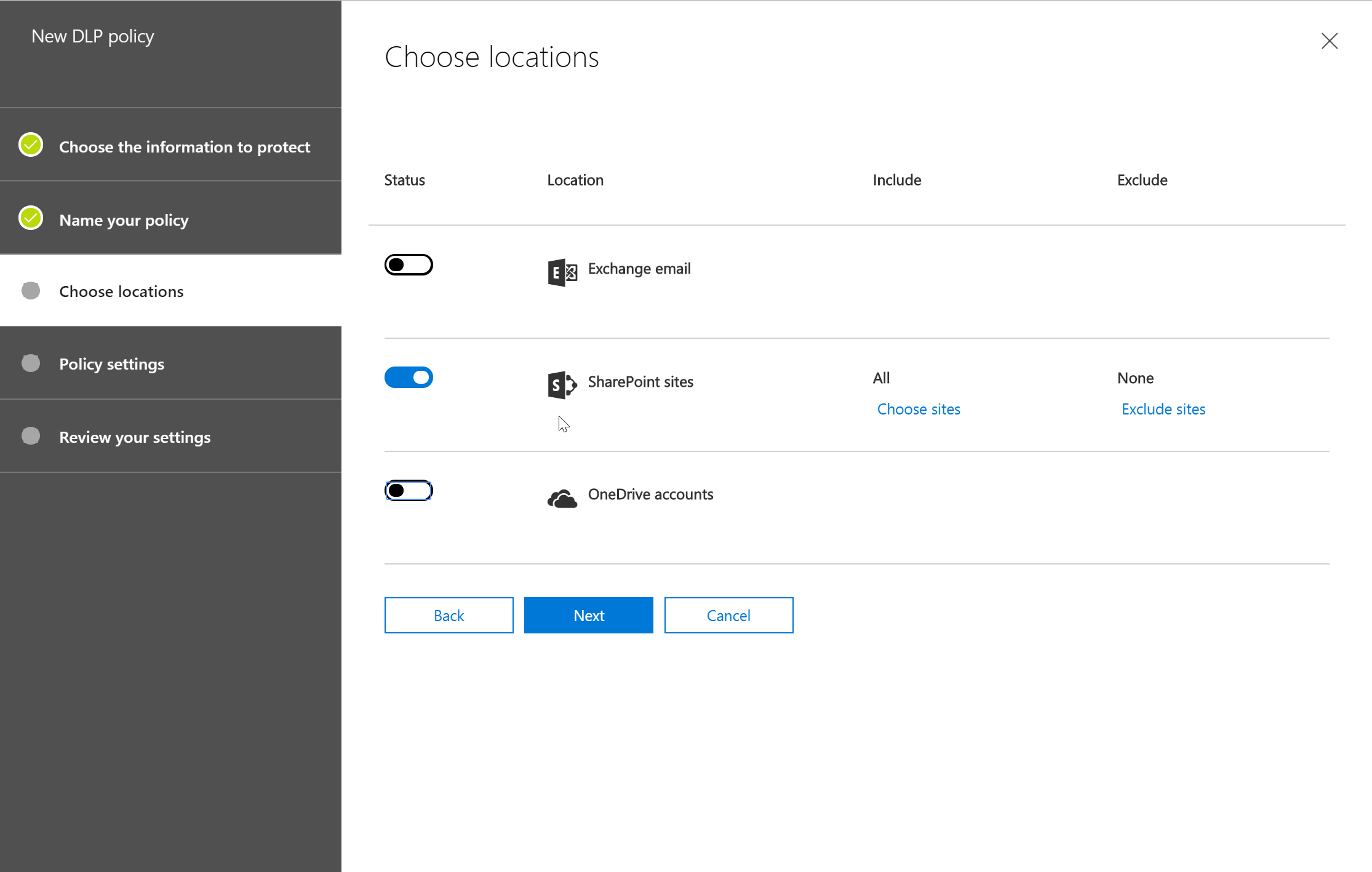
- After the above, we will set rule settings for the DLP policy where we will select the label to which the policy to apply, then select the policy tips, block sharing rules and override rules as shown in the below screenshots. We could also set the admins (provided) to get notified when such as content is shared externally.
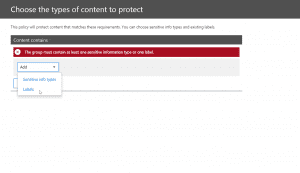
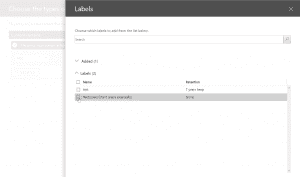
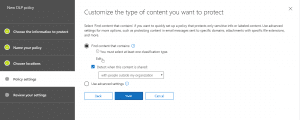
- Next, we could allow the users to override the policy if needed. For this blog and our requirement, we had decided to not allow it to happen.
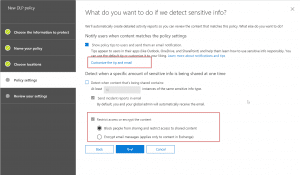
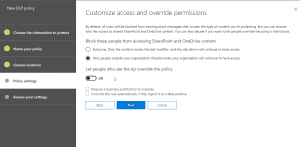
- After this is setup, we could turn on the DLP policy so that it could start applying the rules. There doesn’t seem to be any wait time for applying the policy later but give it some time if you don’t see it happening right away.
- Now the policy is enabled and if the label are published, the user can then apply the label on a content as shown in below screenshot.
Note: In some cases, it takes about 2-3 min for the policy to be effective on the content after applying the label so give it some time.
- After the label is effective after 2-3 min wait, if the same content is shared with an external user, we get the following error.
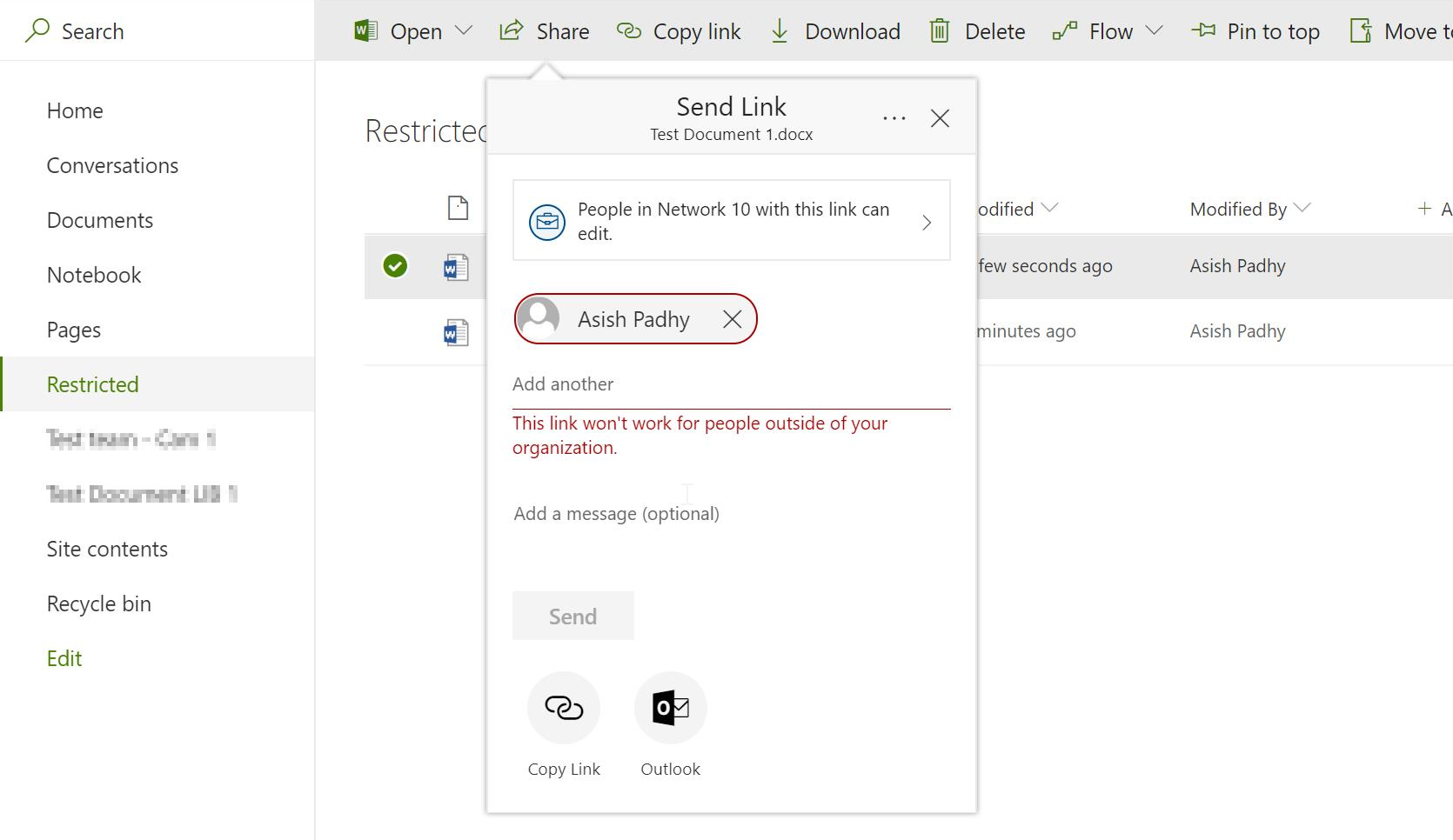
Read More
