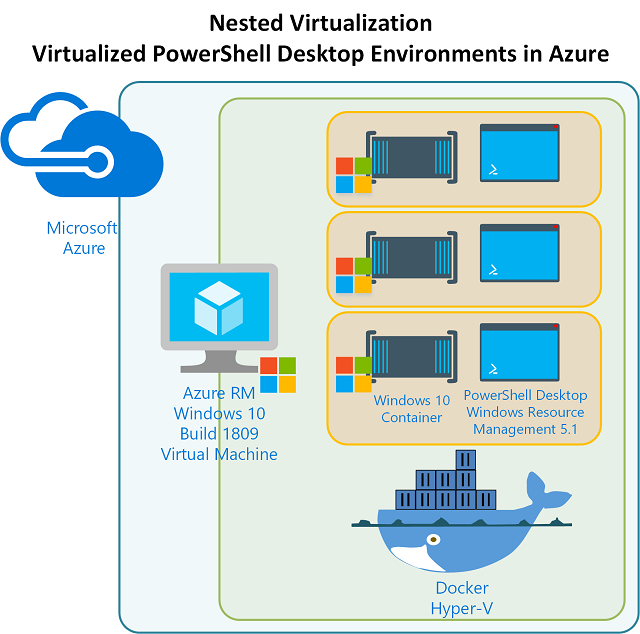
A scenario-based tutorial for Azure Kubernetes Service – Part 2
First published on Nivlesh’s personal blog at https://nivleshc.wordpress.com.
Introduction
In this blog, we will dig a little deeper into Azure Kubernetes Service (AKS). What better way to do this than by building an AKS cluster ourselves! Just a heads-up, I will be using terminology that was introduced in part 1 of this mini-blog series. If you haven’t read it, or need a refresher, you can access it at https://blog.kloud.com.au/2019/03/04/a-scenario-based-tutorial-for-azure-kubernetes-service-part-1/
Let’s start by describing the AKS cluster architecture.… [Keep reading] “A scenario-based tutorial for Azure Kubernetes Service – Part 2”