CyberArk PAM- Eliminate Hard Coded Credentials using Java REST API Calls
Still in many Organization hard coded credentials are stored in Application config files for making application-to-application connection, in scripts (ex: scheduled tasks) and config files. Generally, these are high privileged service accounts and its passwords are set to be never changed.
Keeping hard coded credentials always risk to the organizations security posture. CyberArk provides a solution called Application Identity Manager using which, the passwords of Privileged Service Accounts can be stored centrally in Password Vault, logged, rotated and retrieved in many different ways.… [Keep reading] “CyberArk PAM- Eliminate Hard Coded Credentials using Java REST API Calls”
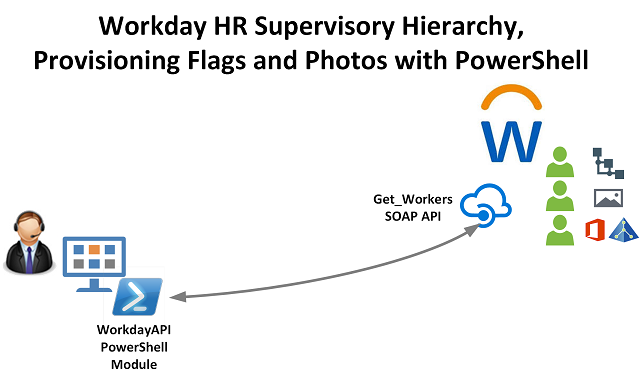
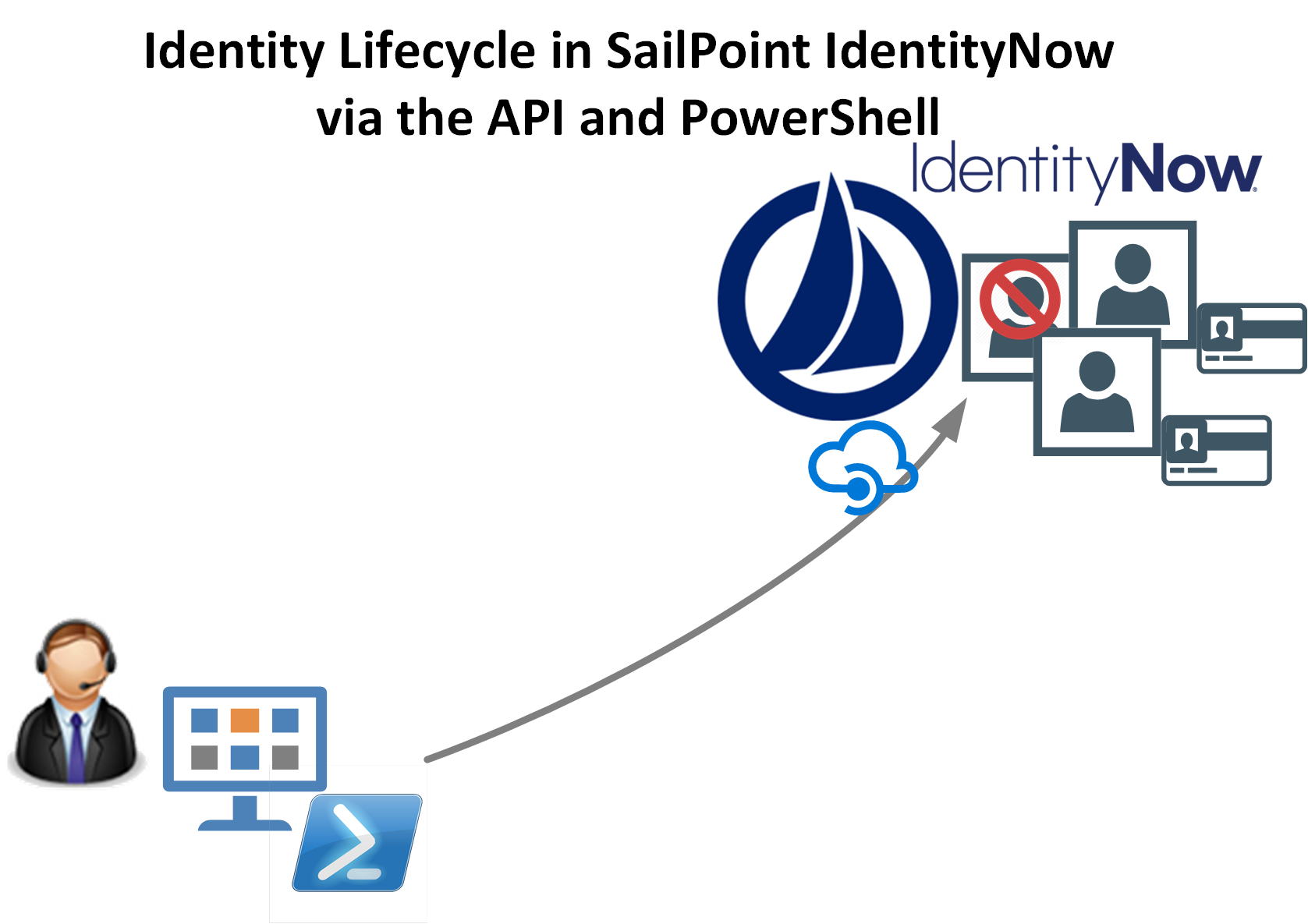
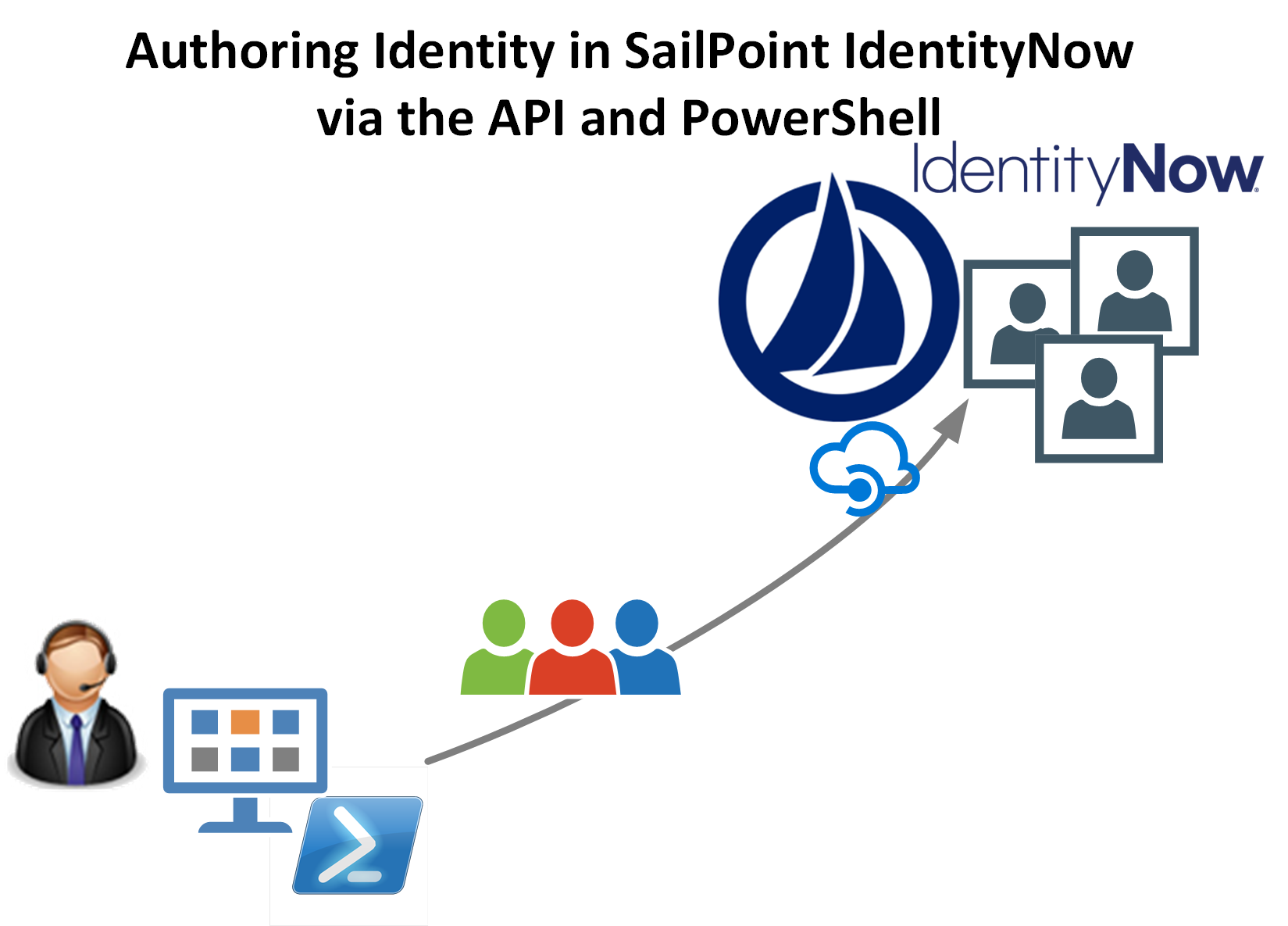


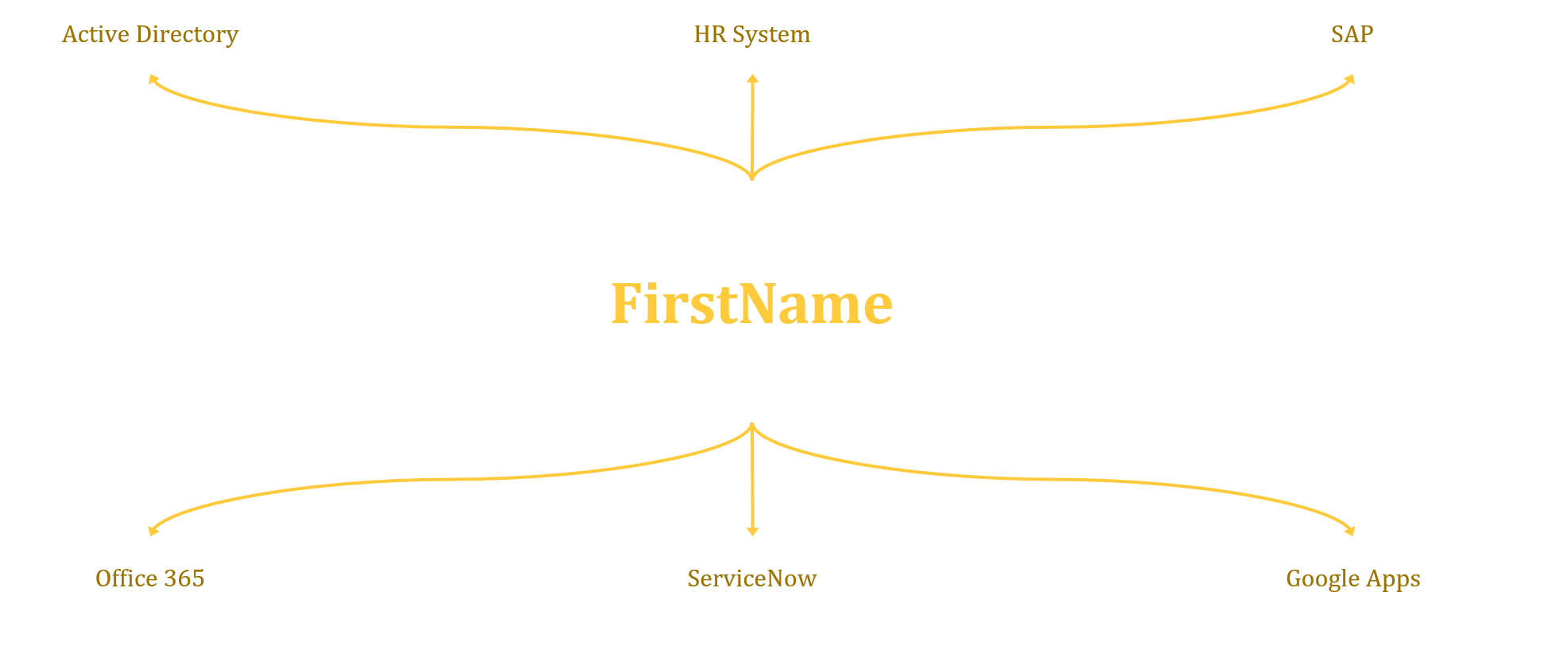
 In this post I will talk about data (aka the source)! In IAM there’s really one simple concept that is often misunderstood or ignored. The data going out of any IAM solution is only as good as the data going in. This may seem simple enough but if not enough attention is paid to the data source and data quality then the results are going to be unfavourable at best and catastrophic at worst.
In this post I will talk about data (aka the source)! In IAM there’s really one simple concept that is often misunderstood or ignored. The data going out of any IAM solution is only as good as the data going in. This may seem simple enough but if not enough attention is paid to the data source and data quality then the results are going to be unfavourable at best and catastrophic at worst.