 In this post I will talk about data (aka the source)! In IAM there’s really one simple concept that is often misunderstood or ignored. The data going out of any IAM solution is only as good as the data going in. This may seem simple enough but if not enough attention is paid to the data source and data quality then the results are going to be unfavourable at best and catastrophic at worst.
In this post I will talk about data (aka the source)! In IAM there’s really one simple concept that is often misunderstood or ignored. The data going out of any IAM solution is only as good as the data going in. This may seem simple enough but if not enough attention is paid to the data source and data quality then the results are going to be unfavourable at best and catastrophic at worst.
With most IAM solutions data is going to come from multiple sources. Most IAM professionals will agree the best place to source the majority of your user data is going to be the HR system. Why? Well simply put it’s where all important information about the individual is stored and for the most part kept up to date, for example if you were to change positions within the same company the HR systems are going to be updated to reflect the change to your job title, as well as any potential direct report changes which may come as a result of this sort of change.
I also said that data can come and will normally always come from multiple sources. At typical example of this generally speaking, temporary and contract staff will not be managed within the central HR system, the HR team simply put don’t care about contractors. So where do they come from, how are they managed? For smaller organisations this is usually something that’s manually done in AD with no real governance in place. For the larger organisations this is less ideal and can be a security nightmare for the IT team to manage and can create quite a large security risk to the business, so a primary data source for contractors becomes necessary what this is is entirely up to the business and what works for them, I have seen a standard SQL web application being used to populate a database, I’ve seen ITSM tools being used, and less common is using the IAM system they build to manage contractor accounts (within MIM 2016 this is through the MIM Portal).
There are many other examples of how different corporate applications can be used to augment the identity information of your user data such as email, phone systems and to a lessor extent physical security systems building access, and datacentre access, but we will try and keep it simple for the purpose of this post. The following diagram helps illustrate the dataflow for the different user types.
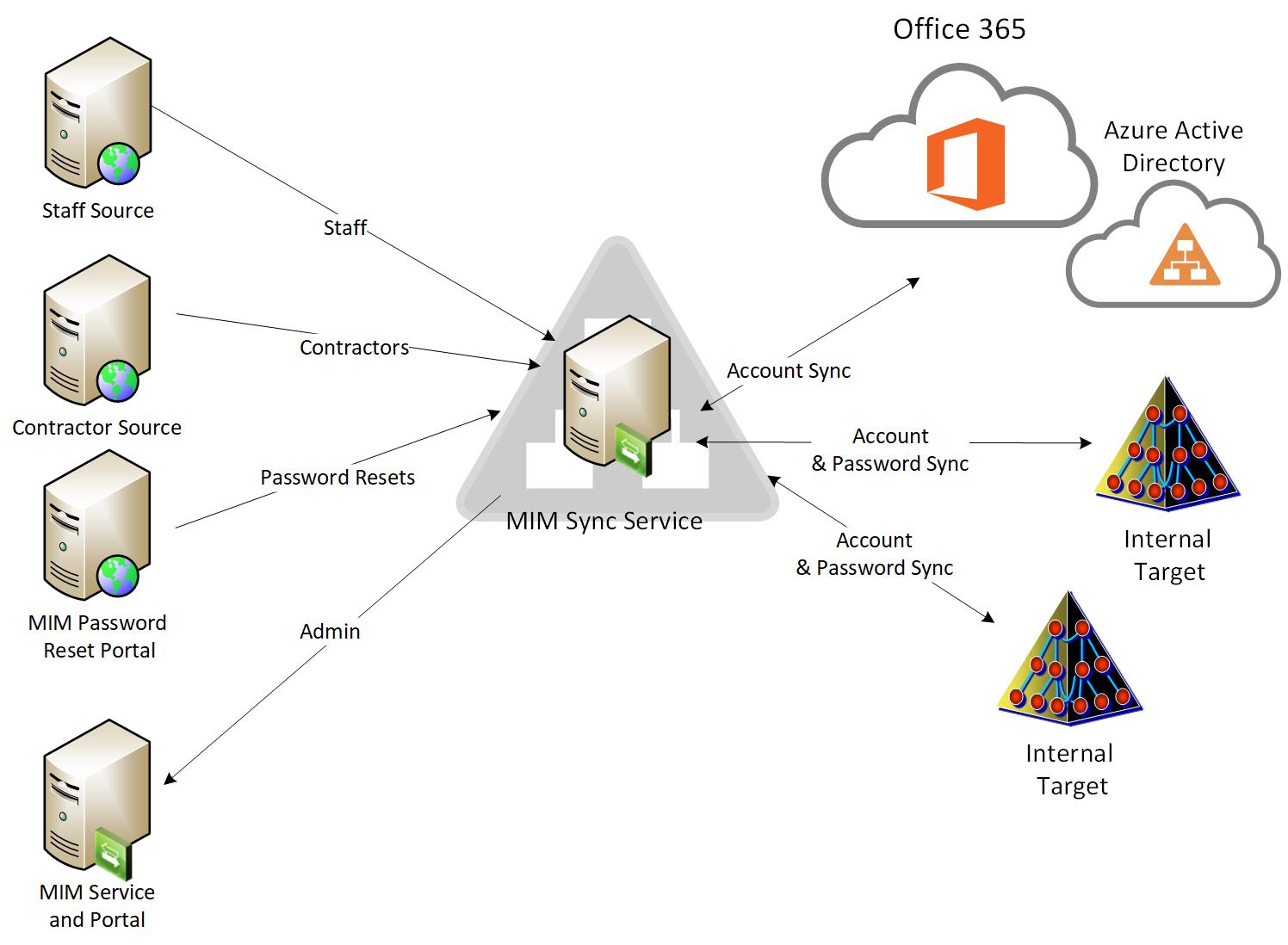
What you will notice from the diagram above, is even though an organisation will have data coming from multiple systems, they all come together and are stored in a central repository or an “Identity Vault”. This is able to keep an accurate record of the information coming from multiple sources to compile what is the users complete identity profile. From this we can then start to manage what information is flowed to downstream systems when provisioning accounts, and we can also ensure that if any information was to change, it can be updated to the users profiles in any attached system that is managed through the enterprise IAM Services.
In my next post I will go into the finer details of the central repository or the “Identity Vault”
So in summary, the source of data is very important in defining an IAM solution, it ensures you have the right data being distributed to any managed downstream systems regardless of what type of user base you have. My next post we will dig into the central repository or the Identity Vault, this will go into details around how we can set precedence to data from specific systems to ensure that if there is a difference in the data coming from the difference sources that only the highest precedence will be applied we will also discuss how we augment the data sets to ensure that we are also only collecting the necessary information related to the management of that user and the applications that use within your business.
As per usual, if you have any comments or questions on this post of any of my previous posts then please feel free to comment or reach out to me directly.
Category:
ADFS, Azure Infrastructure, Business, Identity and Access Management, Office 365, Security, Strategy