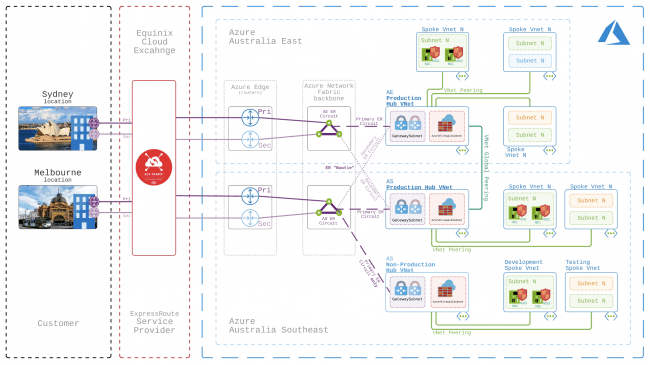
Hub and Spoke network topology in Azure
Originally posted on Lucian.Blog. Follow Lucian on Twitter: @LucianFrango.
Back in late 2016 I was lucky enough to go Microsoft Ignite in Atlanta (USA), which was a bit of a big deal as it was my first major conference. One of the take aways from the various technical sessions on Azure networking I attended was that Microsoft wanted to put a great deal of emphasis on the usage of a Hub and Spoke network topology. … [Keep reading] “Hub and Spoke network topology in Azure”


