Introduction to Series
After recently setting up a storage and DR solution for one of my customers to host their fileserver workload, I thought I’d write a series to document its use and to share any useful tips I found along the way. This first post will explain the technologies that were involved in the solution and how the different components hang together.
What will be covered in the series?
Part 1: Introduction to solution, Microsoft StorSimple device and Windows 2016 file server cluster.
Part 2: Setting up the on-prem StorSimple 8600 device and StorSimple 8020 cloud appliance
Part 4: Failover to cloud appliance in case of DR event
Series Test bed
So, for the solution, I am going to use an on-prem physical StorSimple 8600 device, a 2*node windows 2016 fileserver cluster, 1*windows 2016 fileserver on Azure and StorSimple 8020 cloud appliance on Azure.
On-prem fileserver cluster: The 2*node windows 2016 fileserver cluster will be configured to connect to the StorSimple 8600 through iSCSI to serve as the primary fileshare source.
Azure fileserver: The fileserver on Azure will be configured to be used in the event of DR. The fileserver will be connected to StorSimple 8020 cloud appliance through iSCSI.
To minimize the data transfer on the link between on-prem and Azure environment, StorSimple cloud based snapshots will be utilized instead of native DFSR capability of windows servers.
For an overview of StorSimple devices and windows failover clustering, below links from Microsoft can be followed:
https://docs.microsoft.com/en-us/azure/storsimple/
https://docs.microsoft.com/en-us/windows-server/failover-clustering/failover-clustering-overview
Microsoft Azure StorSimple automatically arranges data in logical tiers based on current usage, age, and relationship to other data. Data that is most active is stored locally, while less active and inactive data is automatically migrated to the cloud. Moreover, StorSimple uses deduplication and compression to reduce the amount of storage that the data consumes.
To enable quick access, StorSimple stores very active data (hot data) on SSDs in the StorSimple device. It stores data that is used occasionally (warm data) on HDDs in the device or on servers at the datacenter. It moves inactive data, backup data, and data retained for archival or compliance purposes to the cloud.
The diagram below provides a high-level view of the Microsoft Azure StorSimple architecture and components used to configure the solution.
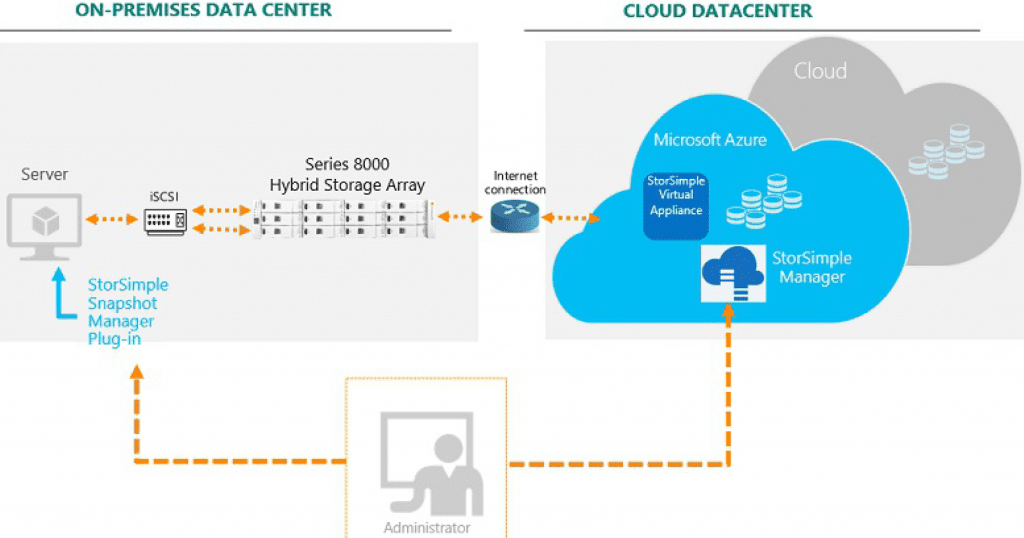
The Microsoft Azure StorSimple device is an on-premises hybrid storage array that provides primary storage and iSCSI access to data stored on it. It includes SSDs and hard disk drives HDDs, as well as support for clustering and automatic failover. It contains a shared processor, shared storage, and two mirrored controllers. Each controller provides the following:
- Connection to a host computer
- Up to six network ports to connect to the local area network (L AN)
- Hardware monitoring
- Non-volatile random access memory (NVRAM), which retains information even if power is interrupted
- Cluster-aware updating to manage software updates on servers in a failover cluster so that the updates have minimal or no effect on service availability
- Cluster service, which functions like a back-end cluster, providing high availability and minimizing any adverse effects that might occur if an HDD or SSD fails or is taken offline
Only one controller is active at any point in time. If the active controller fails, the second controller becomes active automatically.
The StorSimple Cloud Appliance runs on a virtual machine in a Microsoft Azure virtual network, and it is used to back up and clone data from on-prem StorSimple device that can be utilized to provide storage to fileservers in Azure. Cloud appliance can also be used to provision storage for other servers in Azure by creating volumes from Azure storage account.
For this solution the volumes from this appliance will only be provisioned to Azure file server VM and not to the on-prem file server cluster to avoid iSCSI data transfer between on-prem server and Azure.
Windows Fileserver cluster:
Scale-Out File Server is a feature that is designed to provide scale-out file shares that are continuously available for file-based server application storage. Scale-out file shares provides the ability to share the same folder from multiple nodes of the same cluster.
A clustered file server can be configured by using either of the following methods:
- Scale-Out File Server for application data This clustered file server feature was introduced in Windows Server 2012, and it lets you store server application data, such as Hyper-V virtual machine files, on file shares, and obtain a similar level of reliability, availability, manageability, and high performance that you would expect from a storage area network. All file shares are simultaneously online on all nodes. File shares associated with this type of clustered file server are called scale-out file shares. This is sometimes referred to as active-active. This is the recommended file server type when deploying either Hyper-V over Server Message Block (SMB) or Microsoft SQL Server over SMB.
- File Server for general use This is the continuation of the clustered file server that has been supported in Windows Server since the introduction of Failover Clustering. This type of clustered file server, and therefore all the shares associated with the clustered file server, is online on one node at a time. This is sometimes referred to as active-passive or dual-active. File shares associated with this type of clustered file server are called clustered file shares. This is the recommended file server type when deploying information worker scenarios.
Key benefits provided by Scale-Out File Server include:
Active-Active file shares: All cluster nodes can accept and serve SMB client requests. By making the file share content accessible through all cluster nodes simultaneously, SMB 3.0 clusters and clients cooperate to provide transparent failover to alternative cluster nodes during planned maintenance and unplanned failures with service interruption.
Increased bandwidth: The maximum share bandwidth is the total bandwidth of all file server cluster nodes. Unlike previous versions of Windows Server, the total bandwidth is no longer constrained to the bandwidth of a single cluster node; but rather, the capability of the backing storage system defines the constraints. By adding additional nodes, the total bandwidth can be increased.
CHKDSK with zero downtime: CHKDSK in Windows Server 2012 is significantly enhanced to dramatically shorten the time a file system is offline for repair. Clustered shared volumes (CSVs) take this one step further by eliminating the offline phase. A CSV File System (CSVFS) can use CHKDSK without impacting applications with open handles on the file system.
Clustered Shared Volume cache: CSVs in Windows Server 2012 introduced support for a Read cache, which can significantly improve performance in certain scenarios, such as in Virtual Desktop Infrastructure (VDI).
Simpler management: With Scale-Out File Server, the necessary CSVs and file shares can be added after cluster creation as well. It is no longer necessary to create multiple clustered file servers, each with separate cluster disks, and then develop placement policies to ensure activity on each cluster node.
Automatic rebalancing of Scale-Out File Server clients: In Windows Server 2012 R2, automatic rebalancing improves scalability and manageability for scale-out file servers. SMB client connections are tracked per file share (instead of per server), and clients are then redirected to the cluster node with the best access to the volume used by the file share. This improves efficiency by reducing redirection traffic between file server nodes. Clients are redirected following an initial connection and when cluster storage is reconfigured.
In a typical file share environment, usually 8GB RAM and 4 CPUs configuration for the file servers would do the job.
References:
https://docs.microsoft.com/en-us/azure/storsimple/
https://docs.microsoft.com/en-us/windows-server/failover-clustering/failover-clustering-overview