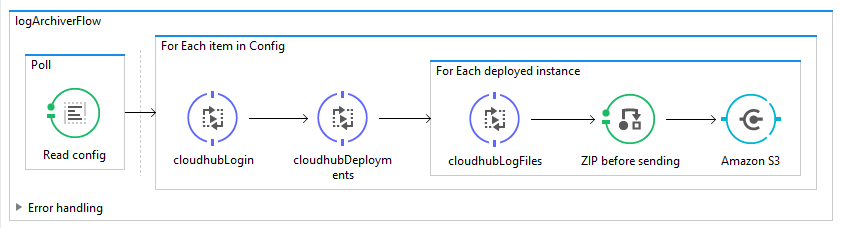
Automate the archiving of your CloudHub application logs
CloudHub is MuleSoft’s integration platform as a service (iPaaS) that enables the deployment and management of integration solutions in the cloud. Runtime Manager, CloudHub’s management tool, provides an integrated set of logging tools that allow support and operations staff to monitor and troubleshoot application logs of deployed applications.
Currently, application log entries are kept for 30 days or until they reach a max size of 100 MB. Often we are required to keep these logs for greater periods of time for auditing or archiving purposes.… [Keep reading] “Automate the archiving of your CloudHub application logs”