Azure Function Proxies for API Mocking
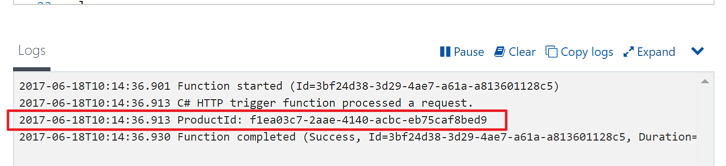
In my previous posts, Is Your Serverless Application Testable? – Azure Logic Apps and API Mocking for Developers, we have looked how to mock APIs with various approaches including Azure API Management, AWS API Gateway, MuleSoft and Azure Functions. Quite recently, Azure Functions Team released a new mocking feature in Azure Function Proxies. With this feature, API mocking can’t be even easier. In this post, I’m going to show how to use this mocking feature in several ways.… [Keep reading] “Azure Function Proxies for API Mocking”