Moving SharePoint Online workflow task metadata into the data warehouse using Nintex Flows and custom Web API
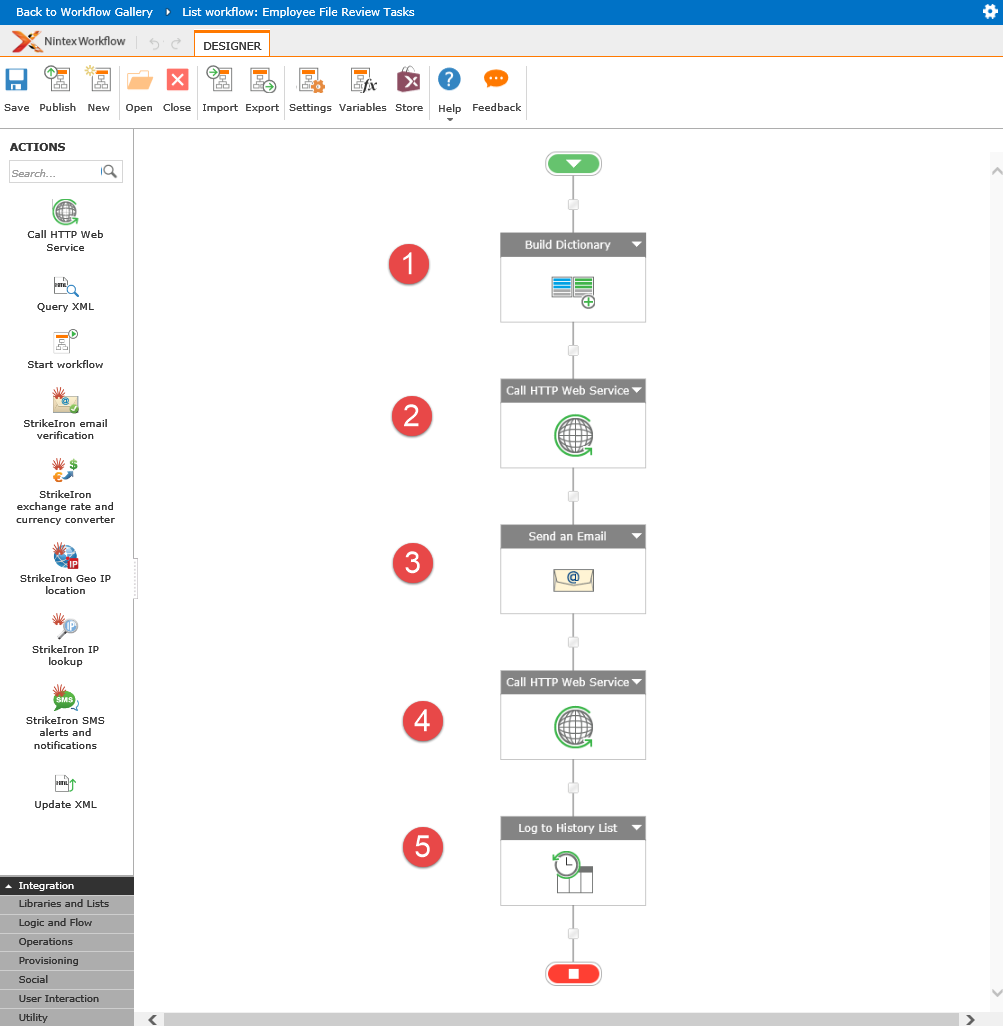
This post suggests the idea of automatic copying of SharePoint Online(SPO) workflow tasks’ metadata into the external data warehouse. In this scenario, workflow tasks are becoming a subject of another workflow that performs automatic copying of task’s data into the external database using a custom Web API endpoint as the interface to that database. Commonly, the requirement to move workflow tasks data elsewhere arises from limitations of SPO. In particular, SPO throttles requests for access to workflow data making it virtually impossible to create a meaningful workflow reporting system with large amounts of workflow tasks.… [Keep reading] “Moving SharePoint Online workflow task metadata into the data warehouse using Nintex Flows and custom Web API”