Azure Building Blocks – The Forgotten IaC Tool
Whilst researching Infrastructure as Code alternatives to Azure Resource Manager templates I stumbled across the Azure Building Blocks (AZBB) tool. It’s not widely adopted and you’ll see why later on this in blog.
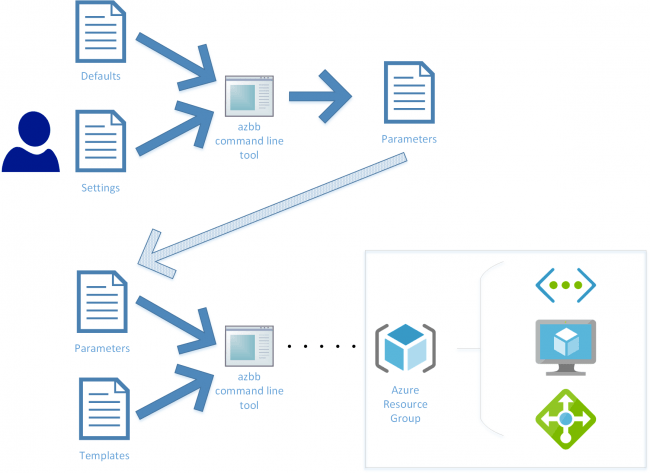
Because I’m not keen on authoring large JSON files (aka ARM templates) for IaC I’m going to put Azure Building Blocks to the test with a simple Hub & Spoke VNET deployment. Later on I’ll also demonstrate the same deployment using an AzureCLI script – my current preferred alternative to ARM Templates – so you’ll see the differences.… [Keep reading] “Azure Building Blocks – The Forgotten IaC Tool”