Calling WCF client proxies in Azure Functions
Azure Functions allow developers to write discrete units of work and run these without having to deal with hosting or application infrastructure concerns. Azure Functions are Microsoft’s answer to server-less computing on the Azure Platform and together with Azure ServiceBus, Azure Logic Apps, Azure API Management (to name just a few) has become an essential part of the Azure iPaaS offering.
The problem
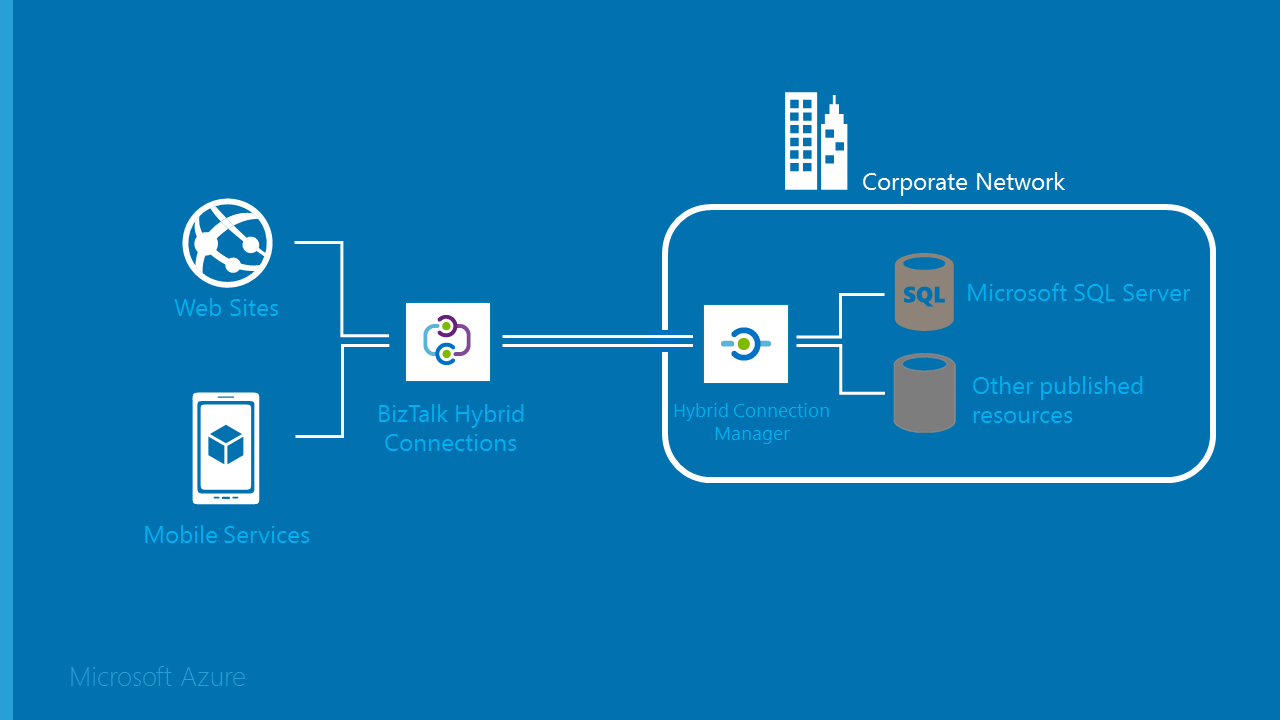
Integration solutions often require connecting legacy systems using deprecating protocols such as SOAP and WS-*.… [Keep reading] “Calling WCF client proxies in Azure Functions”