In this post I will be exploring how can we use MapReduce to implement Gradient Descent algorithm in Hadoop for large scale data. As we know Hadoop is capable of handling peta-byte scale/size of the data.
Before starting, first we need to understand what is Gradient Descent and where can we use it. Below is an excerpt from Wikipedia:
Gradient descent is a first-order iterative optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient (or of the approximate gradient) of the function at the current point. If instead one takes steps proportional to the positive of the gradient, one approaches a local maximum of that function; the procedure is then known as gradient ascent.
[Source: https://en.wikipedia.org/wiki/Gradient_descent ]
If you look at the algorithm, it is an iterative optimisation algorithm. So if we are talking about millions of observations, then we need to iterate those millions of observations and adjust out parameter (theta).
Mathematical notations:

where
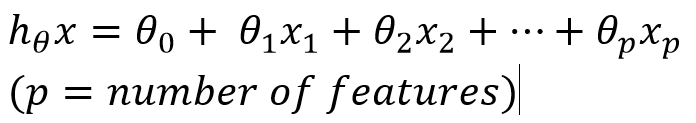

And
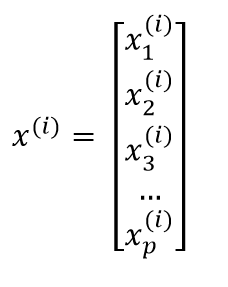
Where p is the number of features.
Now, the question is how can we leverage Hadoop to distribute the work load to minimize the cost function and find the theta parameter?
MapReduce programming model comprises two phases. 1 Map, 2. Reduce shown in below picture. Hadoop gives programmer to only focus on map and reduce phase and rest of the workload is taken care by Hadoop. Programmers do not need to think how I am going to split data etc. Please visit https://en.wikipedia.org/wiki/MapReduce to know about MapReduce framework.
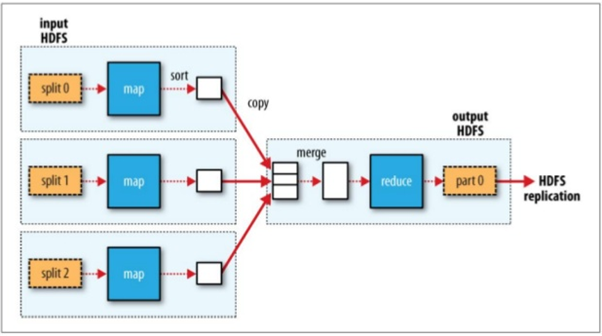
[Multiple mappers with single reducer]
When user uploads data to HDFS, the data is splited and saved in various data nodes. Now we know Hadoop will provide subset of data to each Mapper. So we can program our mapper to emit PartialGradientDescent serializable object. For instance if one split has 50 observations, then that mapper will return 50 partial gradient descent objects. Andrew Ng has well explained at https://www.coursera.org/learn/machine-learning/lecture/10sqI/map-reduce-and-data-parallelism
One more thing, there is only ONE reducer in this example, so reducer will get whole lot of partial gradients, it would be better to introduce combiner so that reducer will get low number of PartialGradientDescent objects or you can apply in-memory combining design pattern for MapReduce which I will cover in next post.
Now let’s get into java map reduce program. I would recommend you to have some reading about Writable in Hadoop.
Here is the mapper code that emits PartialGradientDescent object:
Mapper does following:
- Parses received data into data point and validate it.
- If data point is not valid, then increment the counter (this counter is used to debug how many invalid records were received by mapper)
- calculate partial gradients and emit it.
![]()
Lets have a look at reducer code:
Reducer does following:
- Sum all partial gradients emitted by all mappers
- Update the theta parameters
Reducer receives all the partial gradients, if we are talking about millions observations, it will iterate all to sum. To overcome this issue, we can introduce combiner that does partial sums of partial gradients and emit to reducers. In that case reducer will receive few partial gradients. The other approach is to implement in-mapper combining pattern.
and the last piece of the puzzle is the Driver program that triggers the Hadoop job based on number of iterations you need. Driver program is also responsible for supplying initial theta and alpha.
You can find about PartialGradientWritable at http://blog.mmasood.com/2016/08/implementing-gradient-decent-algorithm.html
That’s it for now. Stay tuned.