
Abstracting complexities around developing, deploying and maintaining software applications have diminished the importance of understanding underlying architecture. While this may work well for today’s aggressive delivery cycles, at the same time, it impacts the ability of engineers to build an efficient, optimal solution which aligns with the internal architecture of the hosting platform. Architects and engineers should be cognizant of the architecture of the hosting environment to better design a system. The same holds good for Microsoft Azure as a hosting provider.
This post is an attempt to throw light on the workflow around deploying workload on Microsoft Azure, the systems involved in this process and their high-level architecture.
Architecture
To start with let’s look at the high level architecture of an Azure datacenter. The following diagram illustrates the physical layout of an Azure Quantum 10 V2 datacenter.
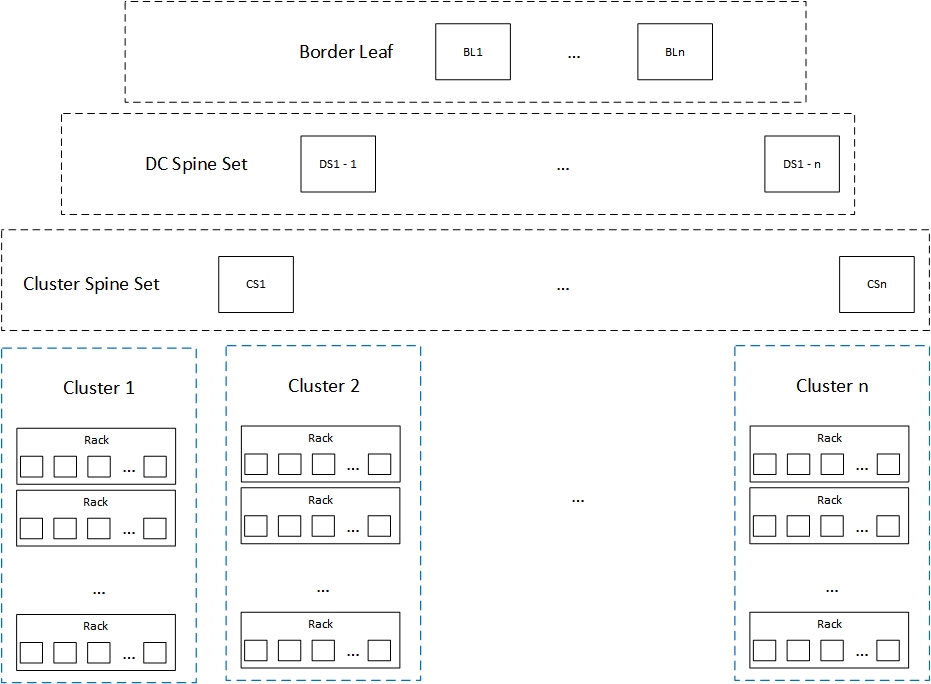
Figure 1.0
Parking the physical layers for a later post, we shall focus on last layer termed as ‘Clusters’ to understand the logical architecture of Microsoft Azure datacenters.
Logical Architecture
Clusters are logical group of server racks. A typical cluster will include 20 server racks hosting approximately 1000 servers. Clusters are also known as ‘Stamps’ internally within Microsoft. Every cluster is managed by a Fabric Controller. Fabric Controller, often considered as the brain of the entire Azure ecosystem is deployed on dedicated resources with in every cluster.
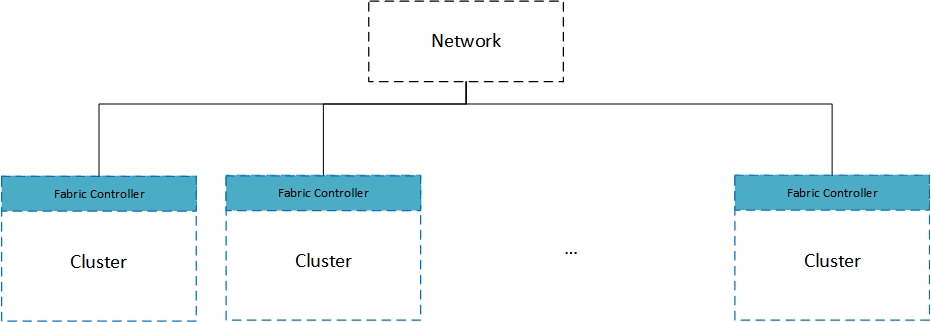
Figure 1.1
Fabric Controller is a highly available, stateful, replicated application. Five machines on every Azure Datacenter cluster are dedicated for Fabric Controller deployment. One server out of the five servers acts as the primary and replicates the state to the other four secondary servers at regular intervals. This is to ensure high availability of this application. Fabric controller is an auto healed system. Hence, when a server goes down, one of the active servers will take charge as the primary and spin up another instance of Fabric Controller.
Fabric controller is responsible for managing the Network, Hardware and the Provisioning of servers in an Azure datacenter. If we visualize the whole datacenter as a machine we can map the server (hardware) as the datacenter itself, kernel (of the operating system) as Fabric controller and processes running on the machine as services hosted on the datacenter. The following image illustrates this perspective:
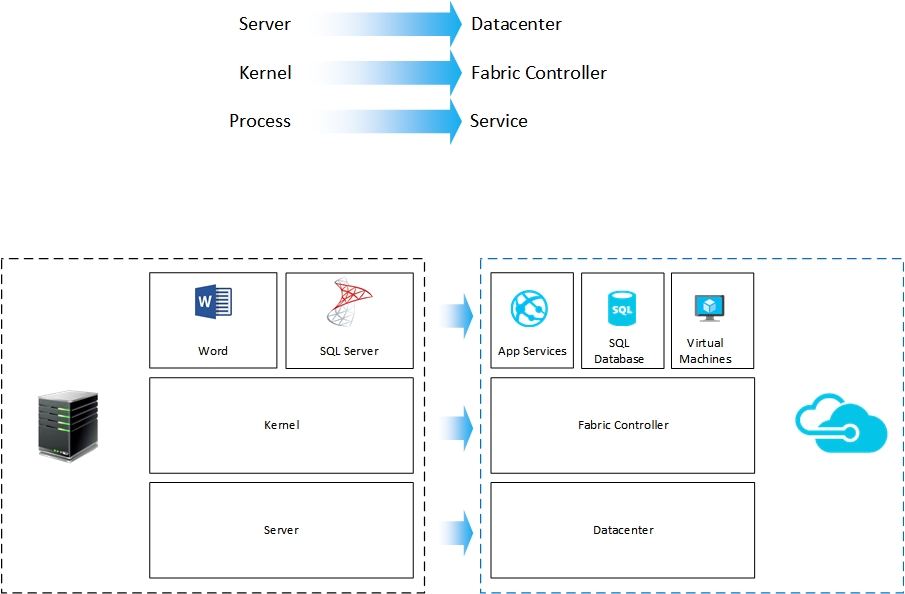
Figure 1.2
Fabric controller controls the allocation of resources (such as compute and storage), both for your deployed custom applications as well as for built-in Azure services. This provides a layer of abstraction to the consumer there by ensuring better security, scalability and reliability.
Fabric controller takes inputs from following two systems:
- Physical Datacenter deployment manager – The physical layout of the machines on the racks, their IP addresses, routers address, certificates for accessing the router, etc. in XML format.
- RDFE (discussed later in the post) – The deployment package and configuration.
Following flowchart captures the boot up tasks performed by the Fabric Controller when it instantiates a cluster:
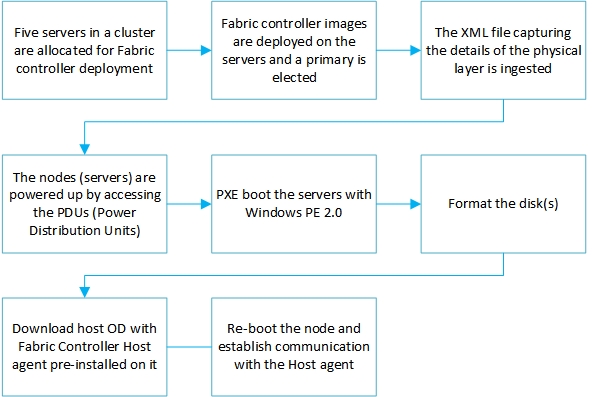
Figure 1.3
Deployment
The following diagram illustrates a high-level view of the deployment process:
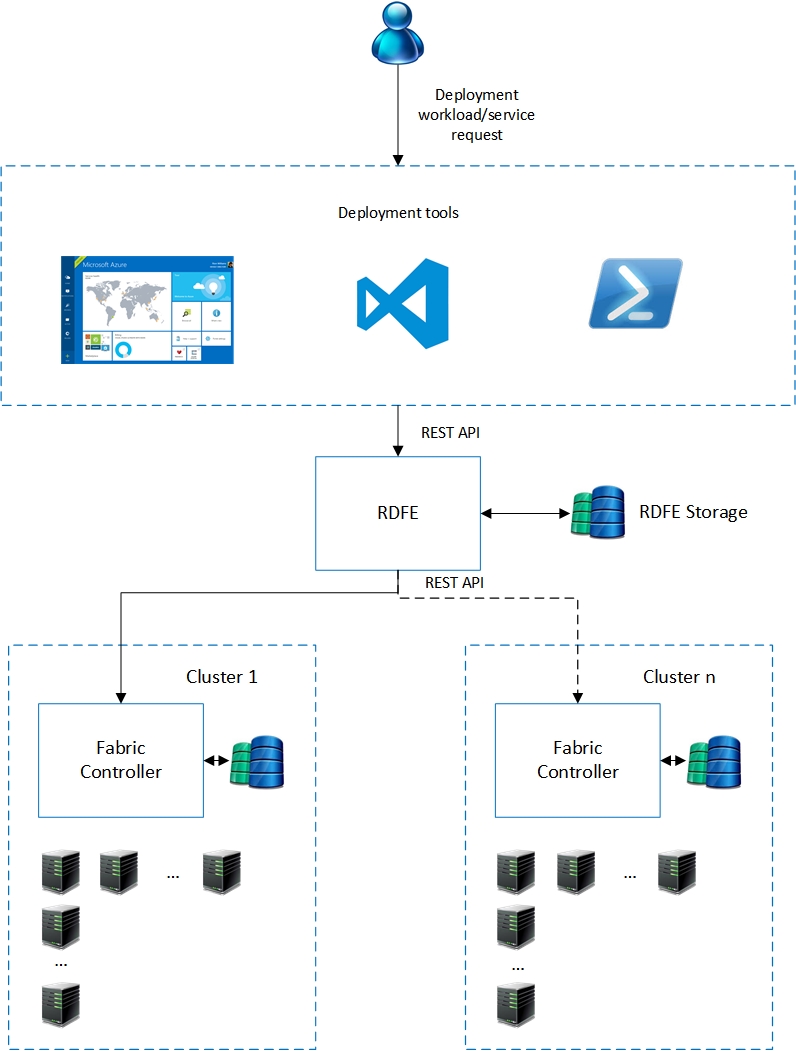
Figure 2.0
Before we understand the deployment workflow, it’s important to familiarize with another software component in the Azure ecosystem which is primarily responsible for triggering a deployment. RDFE (Red Dog Front End), named after the pre-release code name for Microsoft Azure (Red Dog) is a highly available, Azure deployed application which feeds deployment instructions to the Fabric controller. It is responsible for collecting the deployment artefacts, making copies of it, choosing the target cluster for deployment and triggering the deployment process by sending instructions to the Fabric Controller. The following flowchart details the workflow handled by RDFE:
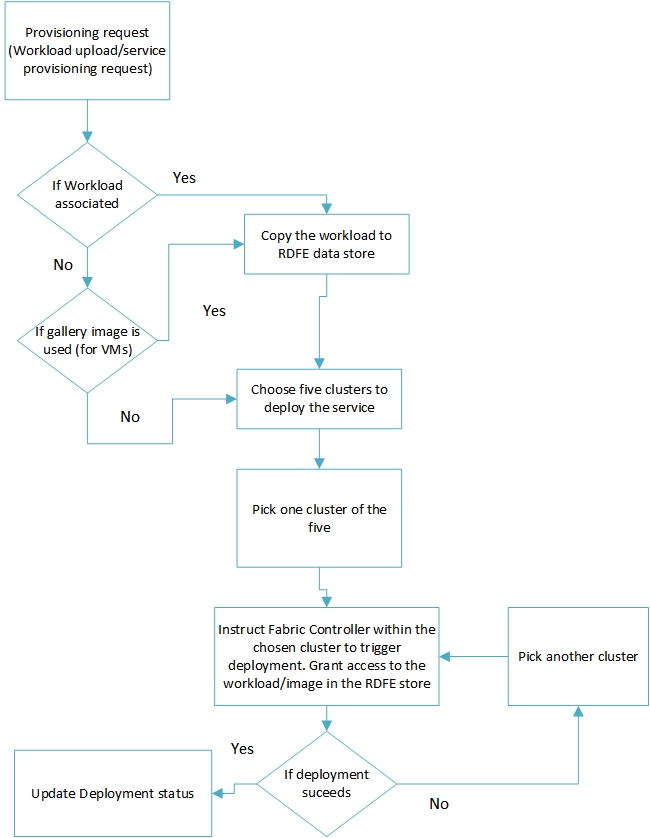
Figure 2.1
A fact to keep in mind is that Azure portal is stateless and so are the management APIs. During a deployment, the uploaded artefacts are passed on to RDFE which stores these artefacts in a staging store (RDFE store). RDFE chooses five clusters for every deployment. If a cluster fails to complete the deployment operation, RDFE picks another cluster from the other four and restarts the deployment operation.
Once a cluster is picked, the deployment workflow is handed over to the Fabric controller. Fabric controller performs the following tasks to provision the required hardware resources as per the application/service configuration.
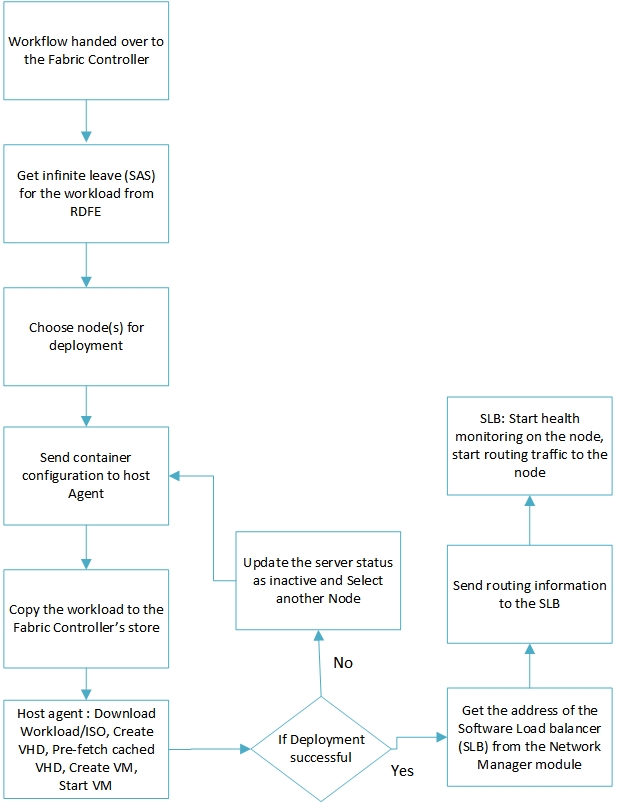
Figure 2.2
Things to remember
Following are few key learnings from my understanding of Azure Architecture:
- Keep your workload small – As discussed in the Deployment section (Figure 2.1, 2.2) , the uploaded workload gets copied multiple times before its deployed on a virtual machine. While deploying an application package, for better efficiency, it is recommended that the code is separated from the other dependent artefacts and only code is packaged as the workload. The dependent artefacts can be separately uploaded into Azure storage or any other persistent store.
- Avoid load balancer whenever you can – Figure 2.2 illustrates steps to update the Azure load balancer post deployment. By default all traffic to a node (server) is routed through the load balancer. Every node(server) is associated with a virtual IP address when it is deployed. Using this to directly communicate with the server reduces one hop in the network route. However, this is not advisable under all circumstances. This may be well suited if the Server is hosting a singleton workload.
- Deploy the largest resource first – The choice of clusters to deploy is made my RDFE in the early stages of deployment as illustrated in Figure 2.1. Not all clusters have all machine configurations available. So if you want co-allocation of servers on a cluster choose to deploy the largest resource first. This will force RDFE to pick a more capable cluster to deploy the workload. All subsequent workloads will be deployed on the same cluster if they are placed under the one affinity group.
- Create syspreped master image VHDs with drivers persisted – Azure optimizes the ISO download operation (on a node) by referring to a pre-fetched cache as shown in Figure 2.2. While using custom images for Virtual Machines, it is advisable to persist drivers so that Azure can utilize pre-fetched driver caching to optimize your deployment
couldn’t find later post “Parking the physical layers for a later post”
can you provide link to the post ?