Q: What is the one unavoidable issue when moving services to the cloud?
Security? Reliability? Ownership? Performance? Nope
A: Latency!
Physics 101
Latency is the amount of time required to communicate between one point and another and is limited by the speed of light. Using high school physics and geography:
Circumference of planet: 40,000km
Longest distance point to point: 20,000km
Speed of Light: 300,000 km/s
Send time: 66mS
Ping time (send and reply): 133mS
That is the theoretical minimum for sending a message to the other side of the planet and getting an answer. This can be confirmed by using the network ping tool available on most operating systems by pinging a server on the other side of the planet.
Pinging www.yammer.com [204.152.18.206] with 32 bytes of data:
Reply from 204.152.18.206: bytes=32 time=222ms TTL=241
But that says 222! In reality, the story is a little more complicated as there are many intermediate hops and decisions to be made along the way which can be revealed using a command like the following which reveals some 13 (for me) hops on the way:
tracert www.yammer.com
1 1 ms 1 ms 2 ms 192.168.2.1
2 19 ms 17 ms 17 ms nexthop.vic.iinet.net.au [203.215.7.251]
3 18 ms 17 ms 17 ms te7-2.mel-pipe-bdr1.iinet.net.au [203.215.6.10]
4 27 ms 28 ms 29 ms xe-7-1-11-0.syd-ult-core1.on.ii.net [203.215.20.102]
5 105 ms 26 ms 27 ms unknown.telstraglobal.net [134.159.126.189]
6 31 ms 31 ms 32 ms i-0-2-4-0.sydo-core01.bi.telstraglobal.net [202.84.223.5]
7 189 ms 188 ms 187 ms i-0-4-0-1.paix-core01.bx.telstraglobal.net [202.84.249.57]
8 187 ms 186 ms 188 ms i-0-0-0-5.paix02.bi.telstraglobal.net [202.84.251.18]
9 184 ms 252 ms 185 ms ge4-0.mpr2.pao1.us.mfnx.net [198.32.176.11]
10 186 ms 229 ms 207 ms xe-1-0-0.mpr2.pao1.us.above.net [64.125.31.62]
11 186 ms 186 ms 186 ms 64.125.195.94.t00969-02.above.net [64.125.195.94]
12 195 ms 186 ms 185 ms 204.152.18.38
13 187 ms 188 ms 187 ms 204.152.18.206
The effect of this time lag on end users is normally much worse than a few mS because chatty solutions that worked well on the internal infrastructure are stretched across a latent link multiplying the lag effect. So what strategies can be used to minimise the impact of latency? Essentially all solutions involve some means of bringing the content closer to the end user and putting in place a mechanism for keeping it up to date. That is otherwise known as “caching”.
Everybody wants the all the latest data immediately, however when dealing with a global networked architecture as we do with Cloud, that is not possible.
Brewers CAP Theorem
The above is an example of Brewers CAP theorem at play.
To cut a long story short, we need to strike a trade-off between which of Consistency, Availability or Partitioning and decide which is going to be sacrificed so we can scale a system globally.
- “Partitioning”: tradeoff-Break up the data set and keep local data local.
- “Availability”: tradeoff-Responses may take longer or outage windows experienced.
- “Consistency”: tradeoff-Sometimes the data you get won’t be exactly right.
Turns out the last strategy, although it sounds dangerous is happening all the time, from your browser to your proxy server to the ISP provider, to Akamai (or similar) the web server and beyond. Our view of the Internet is blurred as we are always browsing with our cache-coloured glasses that presents a view time-shifted from the one at the source. As users our expectation of performance and immediacy has overruled correctness.
We can see the result when you choose items in Amazon, drop them in your shopping cart only to find they are “on back order” once at the checkout. When you put an item in the shopping basket, you’re not taking a lock on your item and decrementing a great big global product counter. You’re viewing a delayed estimation of what is actually available in the warehouse.
Q: So what’s all this got to do with Cloud?
A: When you choose to move to Cloud you’re making a trade-off between the cost of providing the service and one or more of the “CAPs”.
And that’s where caching comes in. It is very good at giving the illusion of Availability by quietly delivering Inconsistency.
Caching
Caching is happening all the time without you even being aware of it.
A hidden but very effective cache is the one that was quietly deployed between Outlook and Exchange. Starting life as an option for laptop users who wanted to do emails while disconnected on the plane has become the default for all Outlook users regardless of connectivity. When was the last time you saw “server not available” error in Outlook stopping you from opening or answering any emails? This is also the same strategy (and for the same purpose) which has emerged underpinning SharePoint Workspace and now SkyDrive Pro.
Another cache is quietly doing its work every time you browse to a site. The requesting URLs and the resulting responses are being saved away in your browser cache, in your proxy server, at your Internet Service Provider and beyond for next time you visit the site.

Those two examples are examples of two broad way of solving the caching problem:
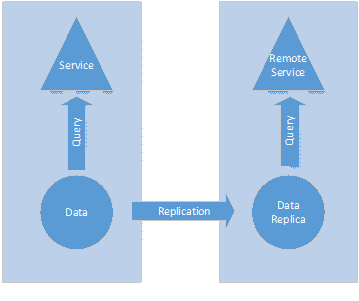
Distributed Query Engine
The first (Outlook, SkyDrive Pro) is to use a single source of data with partitions of that data replicated to distribute the data and query engine to remote locations. This architecture hides the effect of network latency for consuming users and applications and provides a useful scalability point.
This model can be broadly classed as a distributed query engine. That is, not only is the data replicated to the regions, but the entire query engine too (Outlook mail sorting, filtering and searching). The benefit here is the clients can continue to operate off line with a full copy of the (albeit old) data. The problem is it requires access to the original data source for replication.
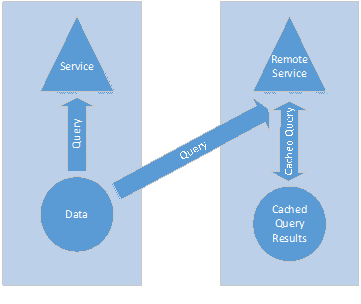
Cached Query and Results
The other model for solving the distribution problem is to use a single data source and distributing the content as stored query and results. That is; query for and then cache the results into local caches. The benefit is, only content that is actually required at a client is cached and it can be implemented at a higher level of abstraction such as web services.
Web Services
Looking at web services in general is it possible to implement a useful cache generically over a variety of data sources? Is it possible to find points into which we can inject and manage some caching delay (Inconsistency) to achieve a scalable, performant, available globally deployed system?
As it turns out, the guys who built the “World Wide Web” invented a highly cacheable protocol called HTTP. A lot of effort has gone into making HTTP cacheable by providing ways to express how much tolerance a client has for old content and how long the server recommends it should be stored. HTTP actually defines a number of different verbs that were created to express different the different actions that could be performed over HTTP.
OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE, CONNECT and MERGE
Each has different verb has different cacheability characteristics. Actions like POST are considered to be an action that changes data (along with PUT and DELETE) and therefore is not to be cached (look at 13.10 here) while GET has the full suite of cacheability options available.
SOAP Dupe
However the meaning, purpose and usefulness of those verbs has become blurred overtime as new higher level protocols like SOAP/WCF have piggy backed solely on the HTTP POST verb as it provided better upstream data support but it has been used to implement updating and retrieving of data.
The side effect of that decision is that it’s very hard to cache web service calls because they use POST under the hood. Most software, frameworks and proxy devices all throw their hands up when it comes to caching of POSTs. So if you want to do it you need to either go below the HTTP protocol (think WAN acceleration) or add something on top. (I’ll implement one of these in a future blog).
The Rise of REST
This is why, in the era of Cloud, REST and higher level protocols like oData have become so popular. They are a return to the world of HTTP verb specific cacheability for web services. The cost is you need to cram all your request data on the URL!
https://klouddev.sharepoint.com/_api/web/lists/getbytitle(‘Documents’)/items(14)/File
Cloud Centralisation
Moving to Cloud involves outsourcing your IT infrastructure to someone and somewhere else. The implications of that can be far reaching. One that is unavoidable is that the economics of computing will force large clumps of computing resources to be located together, close to natural resources like hydroelectric schemes or in naturally cold places where cooling is free.
Q: What does that mean for us as developers?
A: Expect your infrastructure and your users to be separated by distance.
The App That Got Spat
Additionally we are now seeing economics driving cloud services to be provided “multi-tenant”. Which means you and potentially many other users and organisations are sharing the same application, servers and security space. To enable app customisation to work securely so that tenants don’t accidentally (or maliciously) tread on each others toes, a new app development model is emerging where the custom app runs away from the cloud data and services. Either as a separate site owned by the tenant or in the user’s browser or both. For SharePoint Online this is the new “auto-hosted” and “provider-hosted” app models.
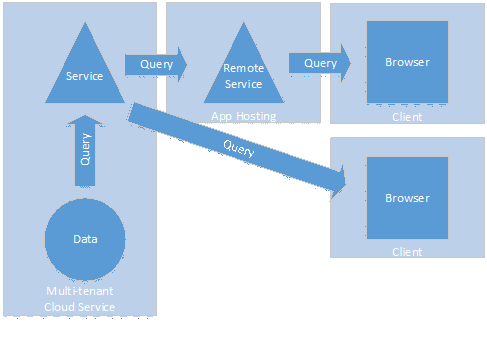
Q: What does that mean for us as developers?
A: Expect your application and your data sources to be separated by distance.
The traditional 3 tier app model just got extended to at least 4 tiers, Data, Service, AppHosting and Browser. The effect is injecting further distance and hops between data and users and putting more reliance on the design of good web service APIs and the ability to call them efficiently and effectively.
What Now?
So caching will become more and more important to app developers working in the Cloud space. To continue to give users the experience they expect but from a more complex and challenging operating environment and geographically dispersed architecture. Over the next two blogs we’ll visit some options for delivering cacheable services over SharePoint which may be extended to other similar SAAS app development models.
Comments are closed.