scTriggers are the third type of server-side code in Cosmos DB. Triggers allow for logic to be run while an operation is running on a document. When a document is to be created, modified, or deleted, our custom logic can be executed – either before or after the operation takes place – allowing us to validate documents, transform documents, and even create secondary documents or perform other operations on the collection. As with stored procedures, this all takes place within the scope of an implicit transaction. In this post, we’ll discuss the two types of triggers (pre- and post-triggers), and how we can ensure they are executed when we want them to be. We’ll also look at how we can validate, modify, and cause secondary effects from triggers.
This post is part of a series of posts about server-side programming for Cosmos DB:
- Part 1 gives an overview of the server side programmability model, the reasons why you might want to consider server-side code in Cosmos DB, and some key things to watch out for.
- Part 2 deals with user-defined functions, the simplest type of server-side programming, which allow for adding simple computation to queries.
- Part 3 talks about stored procedures. These provide a lot of powerful features for creating, modifying, deleting, and querying across documents – including in a transactional way.
- Part 4 (this post) introduces triggers. Triggers come in two types – pre-triggers and post-triggers – and allow for behaviour like validating and modifying documents as they are inserted or updated, and creating secondary effects as a result of changes to documents in a collection.
- Part 5 discusses unit testing your server-side scripts. Unit testing is a key part of building a production-grade application, and even though some of your code runs inside Cosmos DB, your business logic can still be tested.
- Finally, part 6 explains how server-side scripts can be built and deployed into a Cosmos DB collection within an automated build and release pipeline, using Microsoft Visual Studio Team Services (VSTS).
Triggers
Triggers let us run custom logic within the scope of an operation already in progress against our collection. This is different to stored procedures, which are explicitly invoked when we want to use them. Triggers give us a lot of power, as they allow us to intercept documents before they are created, modified, or deleted. We can then write our own business logic to perform some custom validation of the operation or document, modify it in some form, or perform another action on the collection instead or as well as the originally requested action.
Similarly to stored procedures, triggers run within a implicit transactional scope – but unlike stored procedures, the transaction isn’t just isolated to the actions we perform within our code. It includes the operation that caused the trigger. This means that if we throw an unhandled error inside a trigger, the whole operation – including the original caller’s request to insert or modify a document – will be rolled back.
Trigger Behaviour
Triggers have two ways they can be configured: which operations should trigger them and when they should run. We set both of these options at the time when we deploy or update the trigger, using the Trigger Operation and Trigger Type settings respectively. These two settings dictate exactly when a trigger should run.
The trigger operation specifies the types of document operations that should cause the trigger to fire. This can be set to Create (i.e. fire the trigger only when documents are inserted), Delete (i.e. fire the trigger only when documents are deleted), Replace (i.e. fire the trigger only when documents are replaced), or All (fire when any of these operations occur).
The trigger type specifies when the trigger should run with respect to the operation. Pre-triggers run before the operation is performed against the collection, and post-triggers run after the operation is performed. Regardless of when we choose for the trigger to run, the trigger still takes place within the transaction, and the whole transaction can be cancelled by throwing any unhandled error within either type of trigger.
Note that Cosmos DB also runs a validity check before it starts executing any pre-triggers, too. This validity check ensures that the operation is able to be performed – for example, a deletion operation can’t be performed on a document that doesn’t exist, and an insertion operation can’t be performed if a document with the specified ID already exists. For this reason, we won’t see a pre-trigger fire for invalid requests. The following figure gives an overview of how this flow works, and where triggers can execute our custom code:
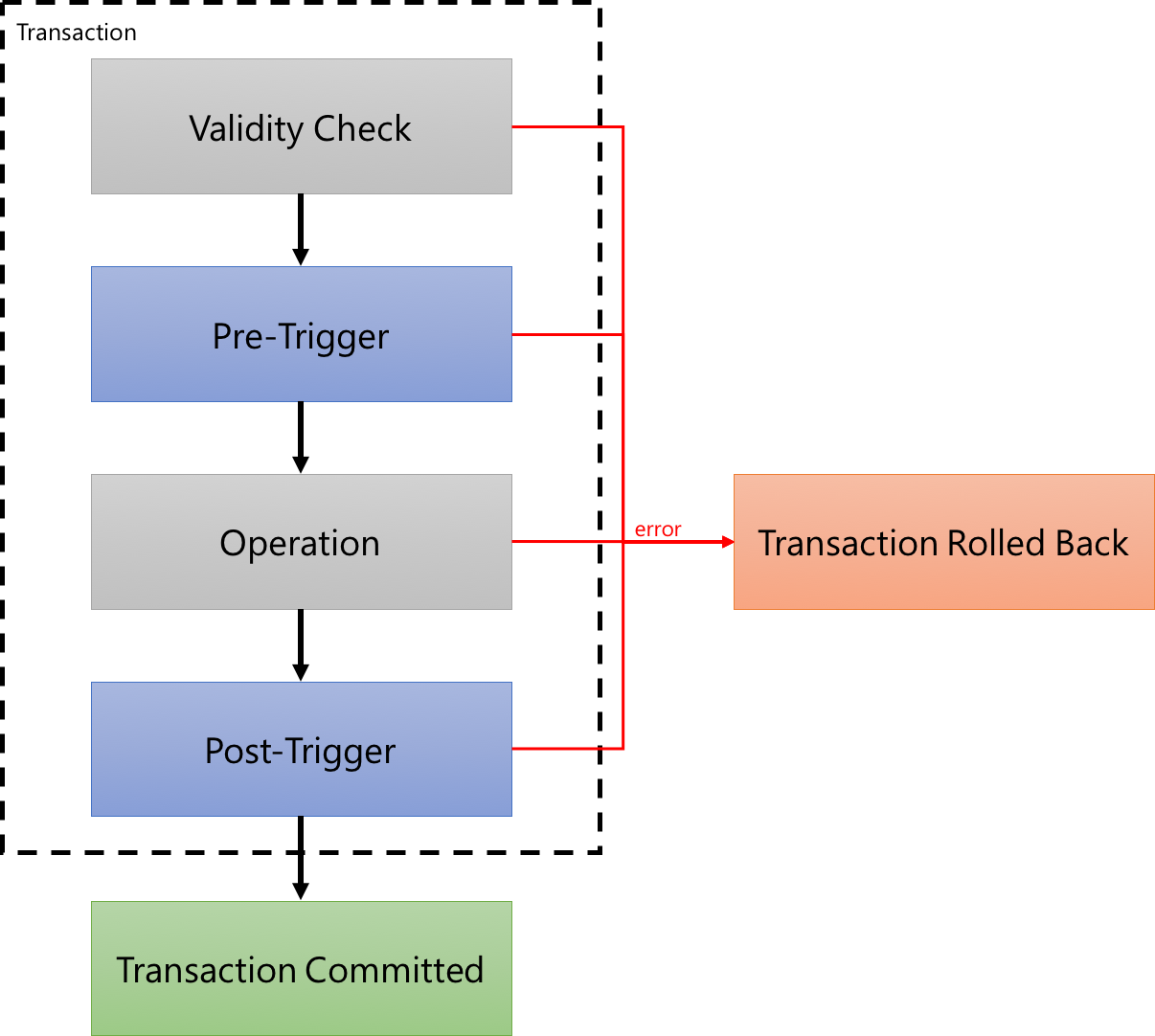
If we want to filter to only handle certain sub-types of documents, for example based on their properties, then this can be done within the trigger logic. We can inspect the contents of the document and apply logic selectively.
Working with the Context
Just like in stored procedures, when we write triggers we have access to the context object through the getContext() method. In triggers, we’ll typically make use of the Collection object (getContext().getCollection()), and depending on the type of trigger we’ll also use the Request object (getContext().getRequest()) and potentially the Response object (getContext().getResponse()).
Request
The Request object gives us the ability to read and modify the original request that caused this trigger to fire. We might choose to inspect the document that the user tried to manipulate, perhaps looking for required fields or imposing our own validation logic. Or we can also modify the document if we need to. We’ll discuss how we do this below.
If you’ve set up a trigger to fire on all operations, then we might sometimes need to find out which operation type has been used for the request. The request.getOperationType() function can be used for this purpose. Please note that the getOperationType() function returns a string, and somewhat confusingly, the possible values that it can return are slightly different to the operation types we discussed above. The function can return one of these strings: Create, Replace, Upsert, or Delete.
Collection
The Collection object can be used in much the same way as in a stored procedure, so refer to part 3 of this series for more details on how this works. In summary, we can retrieve documents by their ID (readDocument()), perform queries on the documents in the collection (queryDocuments()), and pass in parameterised queries (using another overload of the queryDocuments() function). We can also insert documents (createDocument()), modify existing documents (replaceDocument()), upsert documents (upsertDocument()), and delete documents (deleteDocument()). We can even change documents that aren’t directly being modified by the operation that caused this trigger.
Response
The Response object is only available in post-triggers. If we try to use it from within a pre-trigger, an exception will be thrown by the Cosmos DB runtime. Within post-triggers, the Response represents the document after the operation was completed by Cosmos DB. This can be a little unclear, so here’s an example. Let’s imagine we’re inserting a simple document, and not including our own ID – we want Cosmos DB to add it for us. Here’s the document we’re going to insert from our client:
If we intercepted this document within a pre-trigger, by using the Request object, we’d be able to inspect and modify the document as it appears above. Once the pre-trigger has finished its work, Cosmos DB will actually perform the insert, and at that time it appends a number of properties to the document automatically for its own tracking purposes. These properties are then available to us within the Response object in a post-trigger. So this means that, within a post-trigger, we can inspect the Request – which will show the original document as it appears above – and we can also inspect the Response, where the document will look something like this:
We can even use the response.setBody() function to make a change to this response object if we want to, and the change will be propagated to the document in the collection before control returns back to the client.
You might be wondering what a delete operation’s behaviour is. If we examine the body through either the Request or Response during a deletion operation, you’ll see that these functions return the contents of document that is being deleted. This means we can easily perform validation logic based on the contents of the document, such as cancelling the deletion based on the contents of the document. Note that request.setBody() cannot be used within a deletion, although interestingly response.setBody() does appear to work, but doesn’t actually do anything (at least that I can find!).
The combination of the Request, Response, and Collection objects gives us a lot of power to run custom logic at all points along the process. Now we know what we can do with triggers, let’s talk about how we cause them to be fired.
Firing a Trigger
There is a non-obvious aspect to using triggers within Cosmos DB: at the time we perform a collection operation, we must explicitly request that the trigger be fired. If you’re used to triggers in other databases like SQL Server, this might seem like a rather strange limitation. But – as with so much about Cosmos DB – it is because Cosmos DB prioritises performance above many other considerations. Including triggers within an operation will cause that operation to use more request units, so given the focus on performance, it makes some sense that if a trigger isn’t needed for a transaction then it shouldn’t be executed. It does make our lives as developers a little more difficult though, because we have to remember to request that triggers be included.
Another important caveat to be aware of is that at most one pre-trigger and one post-trigger can be executed for any given operation. Confusingly, the Cosmos DB .NET client library actually makes it seem like we can execute multiple triggers of a given type because it accepts a list of triggers to fire, but in reality we can only specify one. I assume that this restriction may be lifted in future, but for now if we want to have multiple pieces of logic executing as triggers, we have to combine them into one trigger.
It’s also important to note that triggers can’t be called from within server-side code. This means that we can’t nest triggers – for example, we can’t have an operation call trigger A, which in turn would insert a document and expect trigger B to be called. Similarly, if we have a stored procedure inserting a document, it can’t expect a trigger to be called either.
And there’s one further limitation – the Azure Portal doesn’t provide a way to fire triggers within Document Explorer. This makes it a little more challenging to test triggers when you’re working on them. I typically do one of three things:
- I write a basic C# console application or similar, and have it use the Cosmos DB client library to perform the operation and fire the trigger; or
- I use the REST API to execute a document operation directly – this is a little more challenging as we need to authenticate and structure the request manually, which can be a little complex; or
- I use a tool named DocumentDB Studio, which is a sample application that uses the Cosmos DB client library. It provides the ability to specify triggers to be fired.
Later in this post we’ll look at DocumentDB Studio. For now, let’s quickly look at how to request that the Cosmos DB .NET client library fire a trigger during an operation too. In the C# application (with a reference to the Cosmos DB library already in place – i.e. one of the .NET Framework or .NET Standard/.NET Core NuGet packages) we can write something like this:
Now that we’ve seen when and how triggers can be fired, let’s go through a few common use cases for them.
Validation
A common application for triggers is to validate documents when they are being modified or inserted. For example, we might want to validate that a particular field is present, or that the value of a field conforms to our expectations. We can write sophisticated validation logic using JavaScript or TypeScript, and then Cosmos DB can execute this when it needs to. If we find a validation failure, we can throw an error and this will cause the transaction to be rolled back by Cosmos DB. We’ll work through an example of this scenario later in this post.
Transformation
We might also need to make a change to a document as it’s being inserted or updated. For example, we might want to add some custom metadata to each document, or to transform documents from an old schema into a new schema. The setBody() function on the Request object can be used for this purpose. For example, we can write code like the following:
Secondary Effects
Sometimes we might need to create or modify a different document in the collection as a result of an operation. For example, we might have to create an audit log entry for each document that is deleted, update a metadata document to include some new information as the result of an insert, or automatically write a second document when we see a certain type of document or operation occurring. We’ll see an example of this later in this post.
Using Triggers for Aggregation
If we need to perform aggregation of data within a collection, it may be tempting to consider using a trigger to calculate running aggregates as data comes into, or is changed within, the collection. However, as noted in part 1 of this series, this is not a good idea in many cases. Although triggers are transactional, transactions are not serialised, and therefore race conditions can emerge. For example, if we have a document being inserted by transaction A, and a post-trigger is calculating an aggregate across the collection as a result of that insertion, it won’t include the data within transaction B, which is occurring simultaneously. These scenarios are extremely difficult to test and may result in unexpected behaviour and inconsistent results. In some situations using optimistic concurrency (with the _etag property of the running aggregate document) may be able to resolve this, but it is very difficult to get this right.
Instead of calculating running aggregate within a trigger, it is usually better to calculate aggregates at query time. Cosmos DB recently added support for aggregations within its SQL API, so querying using functions such as SUM() and COUNT() will work across your data. For applications that require grouping as well as aggregation, such as calculating aggregates by group, an upcoming addition to Cosmos DB will allow for GROUP BY to be used within SQL queries. In the meantime, a stored procedure – similar to that from part 3 of this series – can be used to emulate this behaviour.
Now that we’ve talked through how triggers work and what they can do, let’s try building some.
Defining our Triggers
In this post, we’ll walk through creating two triggers – one pre-trigger and one post-trigger.
Our pre-trigger will let us do some validation and manipulation of incoming documents. In part 1 of this series, we built a UDF to allow for a change in the way that customer IDs are specified on order documents. Now we want to take the next step and ensure that any new order documents are using our new format right from the start. This means that we want to allow for this document to be inserted:
But this one should not be able to be inserted as-is:
So there are four code paths that we need to consider in our pre-trigger:
- The document is not an order – in this case, the trigger shouldn’t do anything and should let the document be inserted successfully.
- The document is an order and uses the correct format for the customer ID – in this case, the trigger should let the document be inserted successfully without any modification.
- The document is an order and uses the old format for the customer ID – in this case, we want to modify the document so that it uses the correct format for the customer ID.
- The document is an order and doesn’t include the customer ID at all – this is an error, and the transaction should be rolled back.
Our post-trigger will be for a different type of business rule. When an order comes through containing an item with a negative quantity, we should consider this to be a refund. In our application, refunds need a second type of document to be created automatically. For example, when we see this order:
Then we should save the order as it was provided, and also create a document like this:
These two example triggers will let us explore many of the features of triggers that we discussed above.
Preparing Folders
Let’s set up some folder structures and our configuration files. If you want to see the finished versions of these triggers, you can access them on GitHub – here is the pre-trigger and here is the post-trigger.
In a slight departure from what we did in parts 2 and 3 of this series, we’ll be building two triggers in this part. First, create a folder named pre for the pre-trigger. Within that, create a package.json and use the following:
In the same folder, add a tsconfig.json file with the following contents:
And create a src folder with an empty file name validateOrder.ts inside it. We’ll fill this in later.
Next, we’ll create more or less the same folder structure for our post-trigger, inside a folder named post. The two differences will be: (1) that the trigger code file will be named addRefund.ts; and (2) the tsconfig.json should have the outFile line replaced with the correct filename, like this:
Our folder structure should now look like this:
- /
- /pre
- package.json
- tsconfig.json
- /src
- validateOrder.ts
- /post
- package.json
- tsconfig.json
- /src
- addRefund.ts
- /pre
Writing the Pre-Trigger
Now let’s fill in our pre-trigger. Open up the empty validateOrder.ts file and add this code:
There’s quite a lot here, so let’s examine it – this time from the bottom up:
- We declare a TypeScript interface named
OrderDocument, which describes the shape of our order documents. We also include a base class namedBaseDocumentto keep things consistent with our post-trigger, described in the next section. As in part 1 of this series, we include both possible ways of expressing the customer ID so that we can reference these two properties within our script. - We declare a TypeScript
const enumnamedDocumentTypes. This is where we’ll define our possible order types. For now we only have one. TypeScript will substitute any reference to the values of these enums for their actual values – so in this case, any reference toDocumentTypes.Orderwill be replaced with the value of the string"order". - Our
validateOrderImplfunction contains our core implementation.Before we start, we also check the operation type that is being performed; if it’s aDeletethen we don’t worry about doing the validation, but forCreateandReplaceoperations we do. Then we pull out the document to validate and then perform the actual validation. If thecustomerIdproperty is set, we transform the document so that it conforms to our expectation. If the customer ID is not provided at all then we throw an error. - Finally, our
validateOrdermethod handles the interaction with thegetContext()function and calls into thevalidateOrderImpl()function. As is the case in earlier parts of this series, we do this so that we can make this code more testable when we get to the part 5 of this series.
That’s all there is to our pre-trigger. Now let’s look at our post-trigger.
Writing the Post-Trigger
Open up the empty addRefund.ts file and add this in:
Let’s explain this, again working from the bottom up:
- Firstly, we declare interfaces for our
OrderDocumentand ourRefundDocument, both of which will inherit (extend) theBaseDocumentinterface. - We also declare our
const enumforDocumentTypes, and in this case we need to track both orders and refunds, so both of these are members of this enum. - Then we define our
addRefundImplmethod. It implements the core business rules we discussed – it checks the type of document, and if it’s an order, it checks to see whether there are any items with a negative quantity. If there are, it creates a refund document and upserts that into the same collection. Like the pre-trigger, this trigger also only runs its logic when the operation type isCreateorReplace, but notDelete. - Finally, the
addRefundmethod is our entry point method, which mostly just wraps theaddRefundImplmethod and makes it easier for us to test this code out later.
Compiling the Triggers
Because we have two separate triggers, we need to compile them separately. First, open a command prompt or terminal to the pre folder, and execute npm run build. Then switch to the post folder and run npm run build again. You should end up with two output files.
In the pre/output/trig-validateOrder.js file, you should have a JavaScript file that looks like the following:
And in the post/output/trig-addRefund.js file, you should have the following JavaScript:
Now that we’ve got compiled versions of our triggers, let’s deploy them.
Deploying the Triggers
As in parts 2 and 3 of this series, we’ll deploy using the Azure Portal for now. In part 6 of this series we’ll look at some better ways to deploy our code to Cosmos DB.
Open the Azure Portal to your Cosmos DB account, select Script Explorer, and then click the Create Trigger button. Now let’s add the contents of the trig-validateOrder.js file into the big text box, enter the name validateOrder, and make sure that the Trigger Type drop-down is set to Pre and that the Trigger Operation drop-down is set to All, like this:
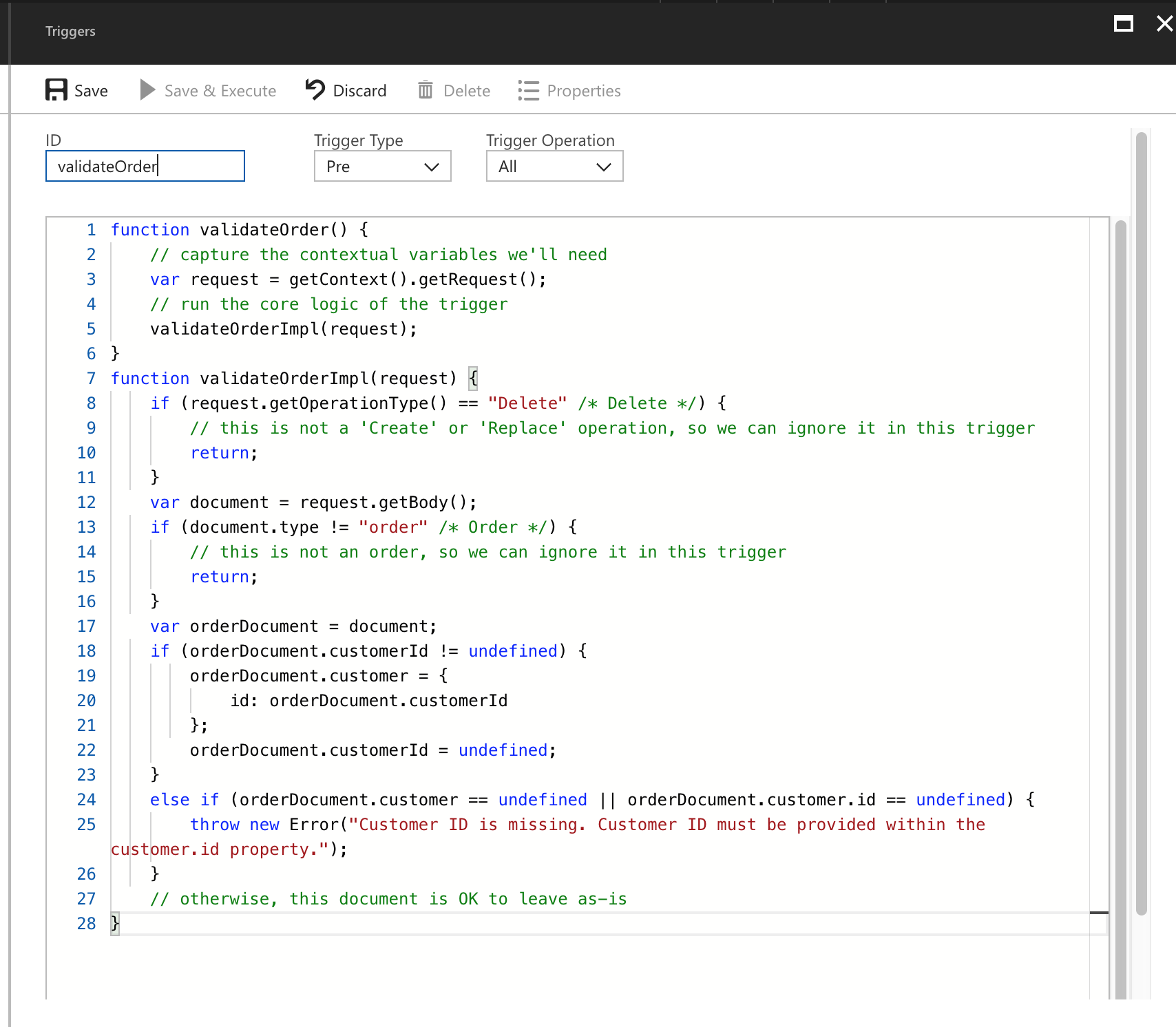
Click Save, close the blade, and click Create Trigger to create our second trigger. This one will be named addRefund, and ensure that Trigger Type is set to Post for this one. Trigger Operation should still be set to All, like this:
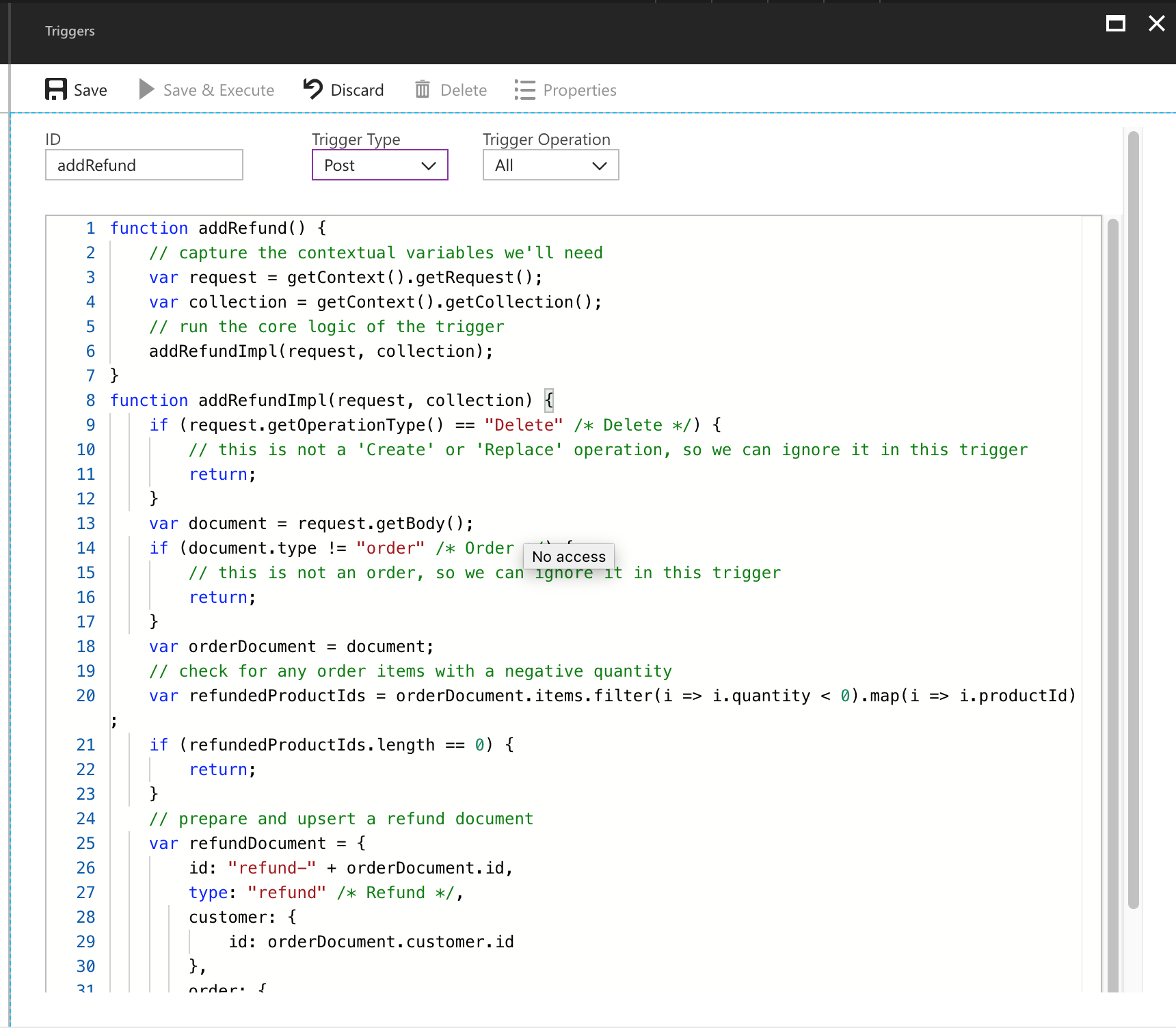
Click Save. Our triggers are now deployed! Let’s test them.
Testing the Triggers
Testing triggers can be a little tricky, because the Azure Portal doesn’t have a way to fire triggers when we work with documents through Document Explorer. This means we have to use another approach to try out our triggers.
DocumentDB Studio is an open-source tool for working with Cosmos DB data. There are several such tools available now, including Azure Storage Explorer and Visual Studio, but other than DocumentDB Studio, I haven’t found any that allow for firing triggers during document operations. Unfortunately DocumentDB Studio is only available for Windows, so if you’re on a Mac or Linux, you may have to look at another approach to fire the triggers, like writing a test console application using the Cosmos DB SDK.
Install the latest release of DocumentDB Studio from the GitHub releases page, and go to File and then Add Account to log in using your Cosmos DB account endpoint and key. This will authenticate you to Cosmos DB and should populate the databases and collections list in the left pane.
Expand out the account, and go to the Orders database and Orders collection. Right-click the collection name and click Create Document:
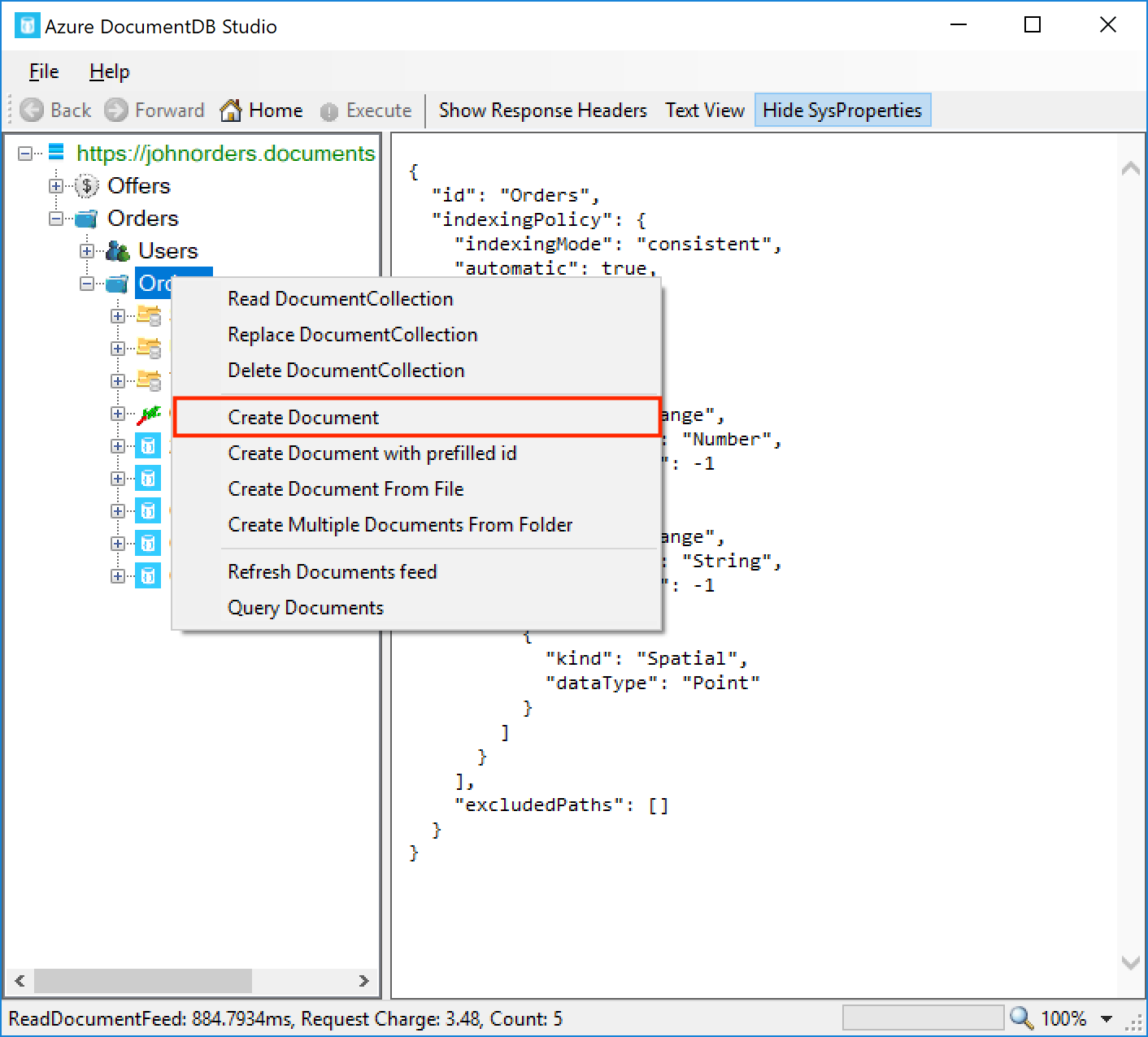
Paste the contents of the following file into the document textbox:
We can instruct DocumentDB Studio to fire triggers by clicking on the RequestOptions tab and deselecting the Use default checkbox. Then in the PreTrigger field, enter validateOrder and in the PostTrigger field, enter addRefund:
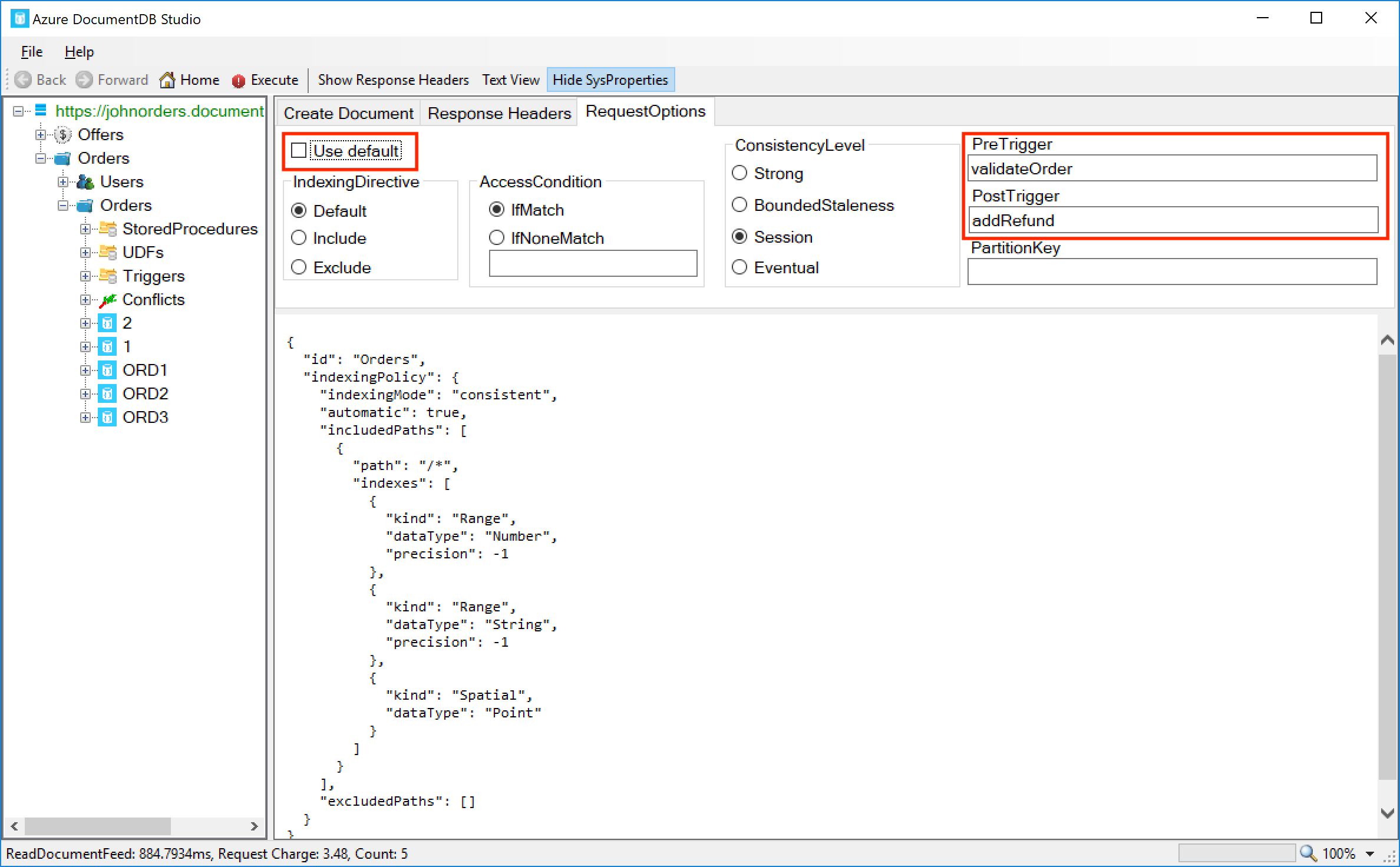
Now we’ve prepared our request, click the Execute button on the toolbar, and we should see an error returned by Cosmos DB:
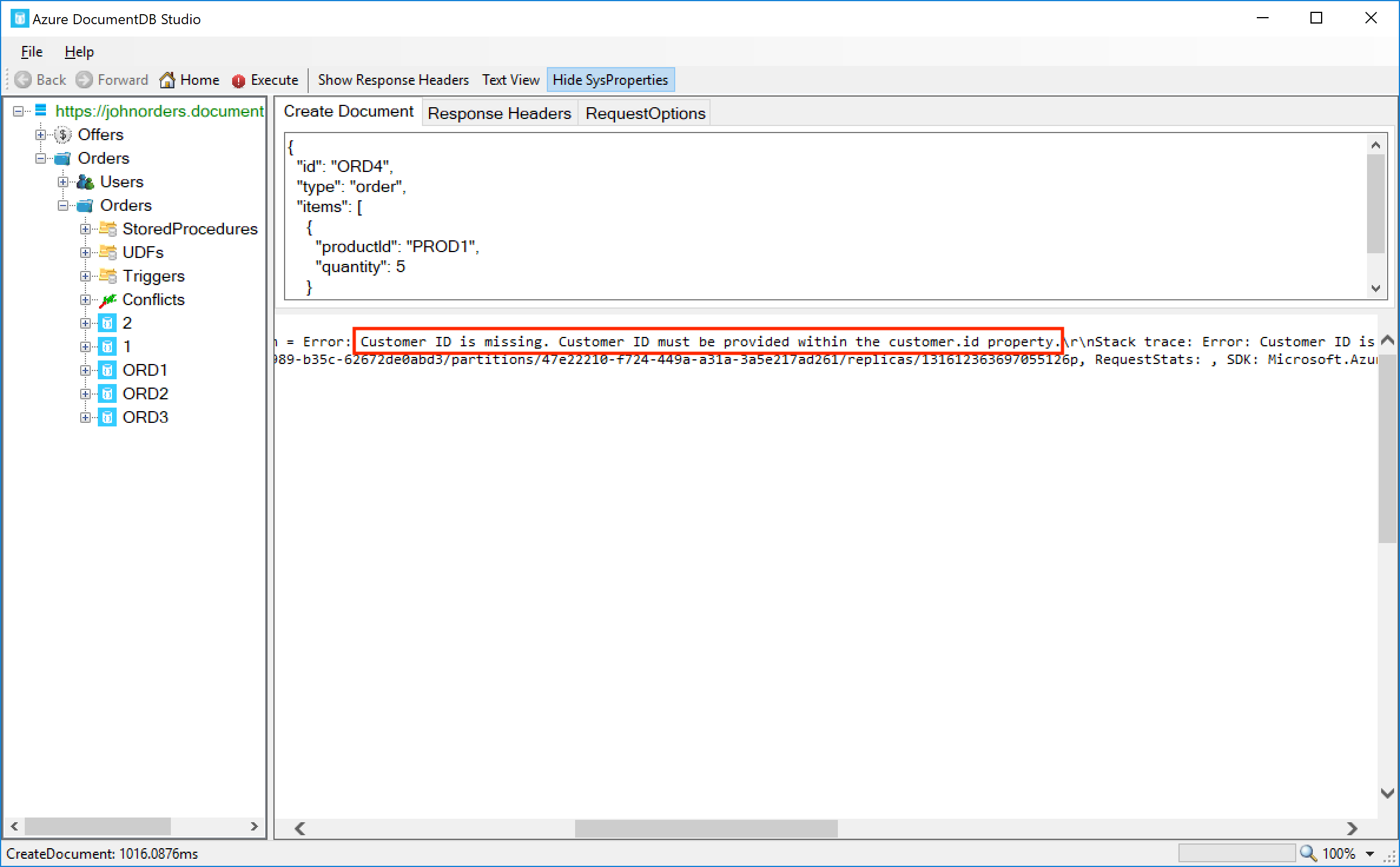
We can see the error we’re getting is Customer ID is missing. Customer ID must be provided within the customer.id property. This is exactly what we wanted – the trigger is noticing that neither the customerId field or the customer.id fields are provided, and it throws an error and rolls back the transaction.
Now let’s try a second document. This time, the customer ID is provided in the old format:
This time, you should see that the order is created, but that it’s been transformed by the validateOrder trigger – the customer ID is now within the customer.id field:
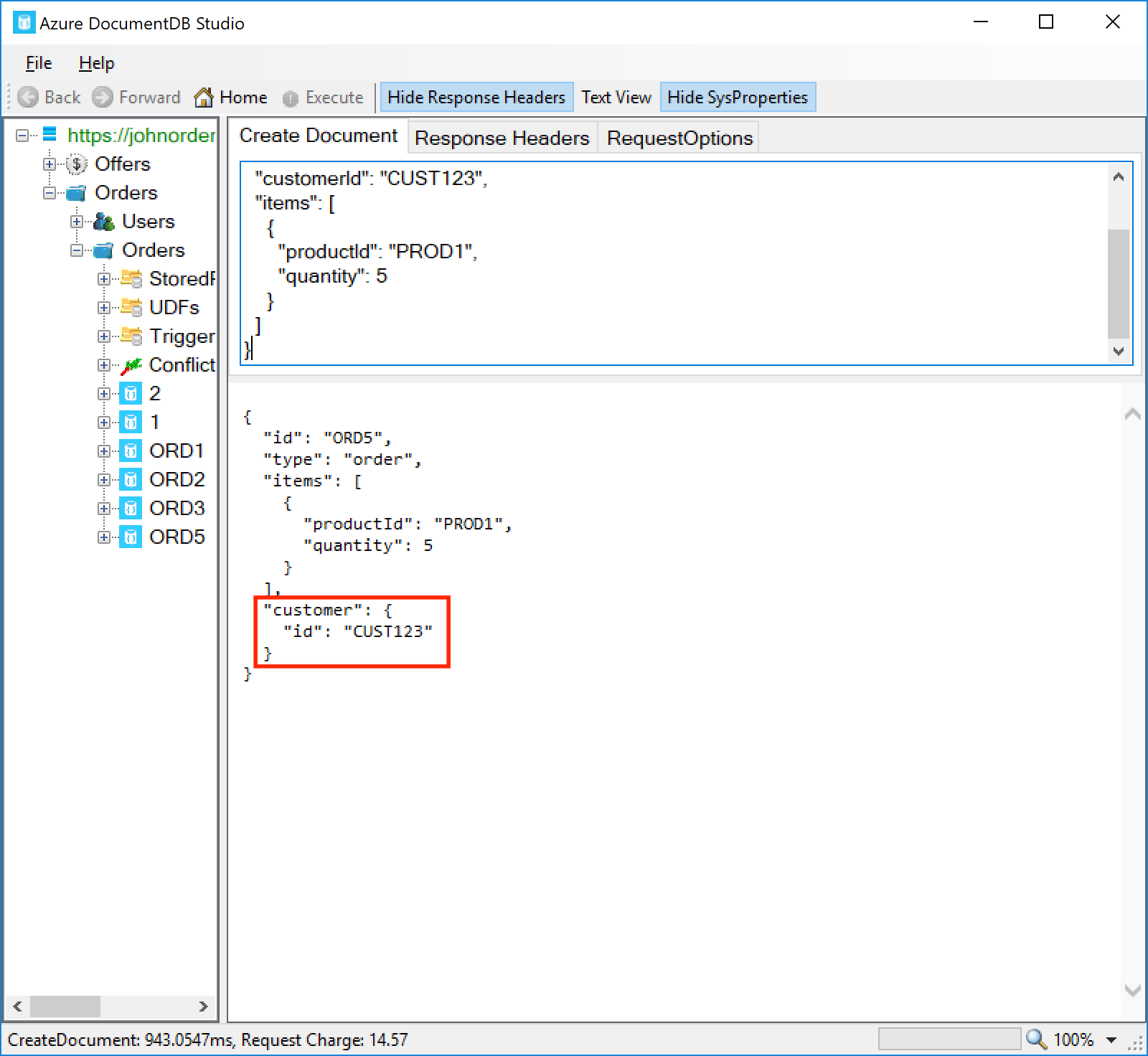
Now let’s try a third document. This one has a negative quantity on one of the items:
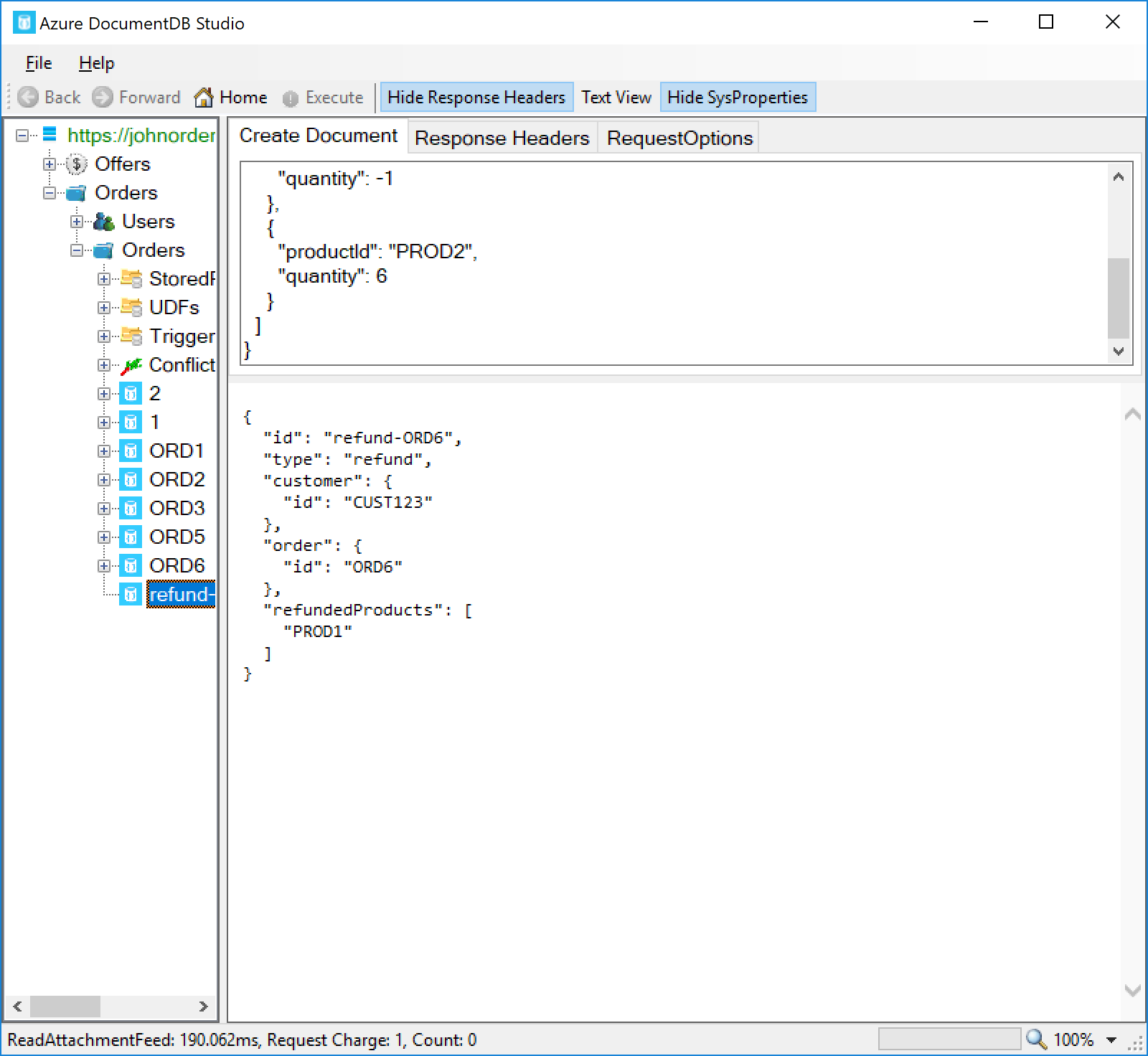
This document should be inserted correctly. To see the refund document that was also created, we need to refresh the collection – right-click the Orders collection on the left pane and click Refresh Documents feed:
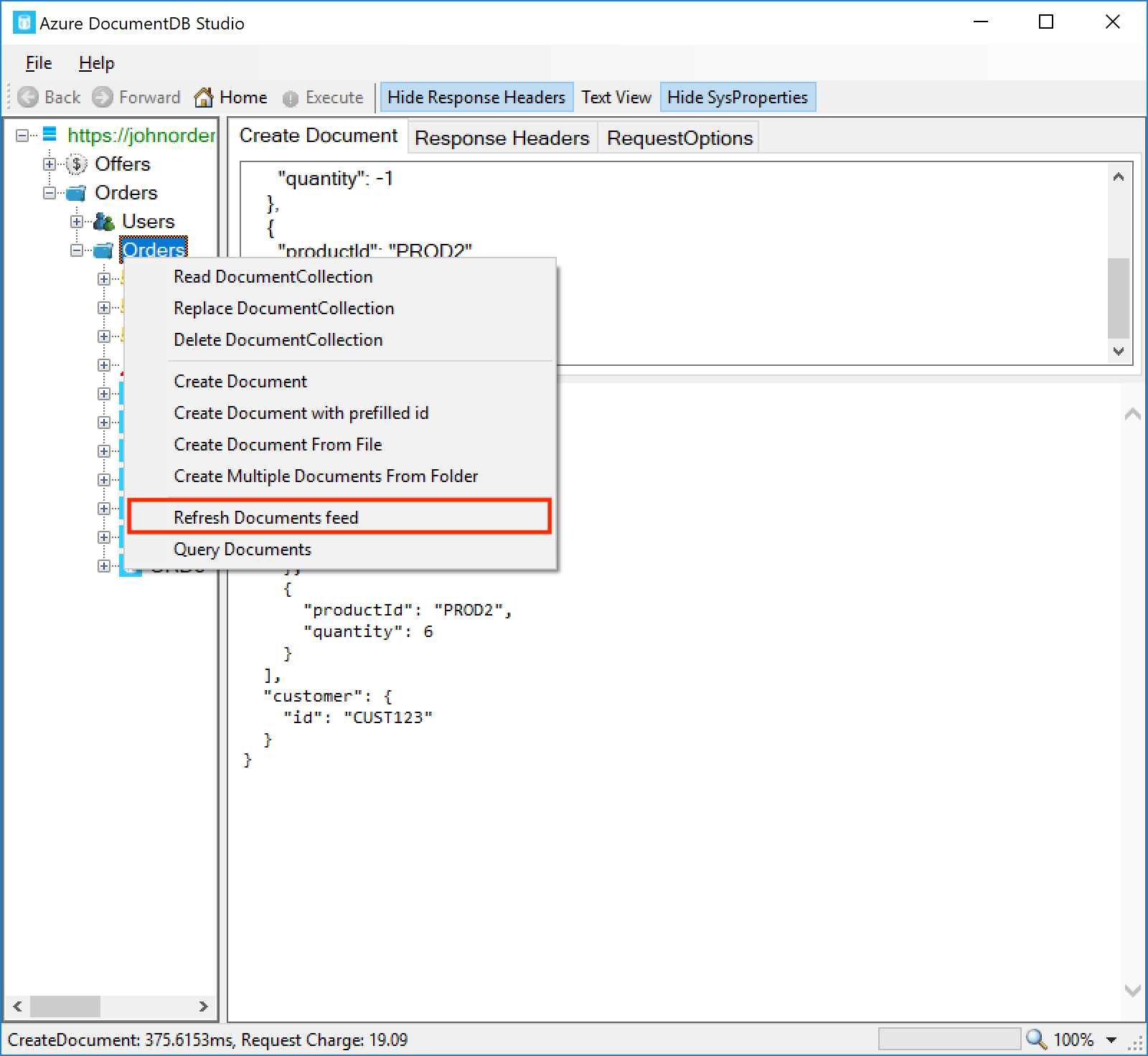
You should see that a new document, refund-ORD6, has been created. The refund document lists the refunded product IDs, which in this case is just PROD1:
Summary
Triggers can be used to run our own custom code within a Cosmos DB document transaction. We can do a range of actions from within triggers such as validating the document’s contents, modifying the document, querying other documents within the collection, and creating or modifying other documents. Triggers run within the context of the operation’s transaction, meaning that we can cause the whole operation to be rolled back by throwing an unhandled error. Although they come with some caveats and limitations, triggers are a very powerful feature and enable a lot of useful custom functionality for our applications. In the next part of this series, we will discuss how to test our server-side code – triggers, stored procedures, and functions – so that we can be confident that it is doing what we expect.
Key Takeaways
- Triggers come in two types – pre-triggers, which run before the operation, and post-triggers, which run after the operation. Both types can intercept and change the document, and can throw an error to cancel the operation and roll back the transaction.
- Triggers can be configured to fire on specific operation types, or to run on all operation types.
- The
getOperationType()method on theRequestobject can be used to identify which operation type is underway, although note that the return values of this method don’t correspond to the list of operation types that we can set for the trigger. - Cosmos DB must be explicitly instructed to fire a trigger when we perform an operation. We can do this through the client SDK or REST API when we perform the operation.
- Only a single trigger of each type (pre- and post-operation) can be called for a given operation.
- The
Collectionobject can be used to query and modify documents within the collection. - The
Requestobject’sgetBody()method can be used to examine the original request, and in pre-triggers,setBody()can modify the request before it’s processed by Cosmos DB. - The
Responseobject can only be used within post-triggers. It allows both reading the document after it was inserted (including auto-generated properties like_ts) and modifying the document. - Triggers cannot be nested – i.e. we cannot have a trigger perform an operation on the collection and request a second trigger be fired from that operation. Similarly a stored procedure can’t fire a trigger.
- Testing triggers can be a little difficult, since the Azure Portal doesn’t provide a good way to do this currently. We can test using our own custom code, the REST API, or by using DocumentDB Studio.
- You can view the code for this post on GitHub. The pre-trigger is here, and the post-trigger is here.
For anyone who looked at an earlier version of this post – the Cosmos DB server-side type definitions have been updated with the new IRequest.getOperationType() method, so the post has been updated to reflect this.
For anyone who looked at an earlier version of this post – the Cosmos DB server-side type definitions have been updated with the new IRequest.getOperationType() method, so the post has been updated to reflect this.
Hi John , thank you for this great article about triggers. really helped.
I was wondering if it is possible to access another collection in the triggers. For example within a pre or post trigger can I access to another collections to look for something or to modify something.
for example, let say I have an Orders collection and I have a OrderEmails collection(listening by a azure function to send email to customer), can I insert a new record into my OrderEmails collection after every Order create operation. in a pre or after hook.
Thanks.
Hi Yazilim, unfortunately it’s not possible to query across collections from a trigger. All server-side operations are run within the context of the collection.
However, I’d also recommend that in the specific case you mentioned (an Orders collection and an OrderEmails collection), you may actually want to combine these into a single collection. Unlike some other databases like SQL Server, there is no requirement that data in the collection has to be of the same type. Instead, it is often better to store heterogeneous data in a collection, perhaps with a field to indicate its type. This also makes the querying scenario a little easier.
Hi John , thank you for this great article about triggers. really helped.
I was wondering if it is possible to access another collection in the triggers. For example within a pre or post trigger can I access to another collections to look for something or to modify something.
for example, let say I have an Orders collection and I have a OrderEmails collection(listening by a azure function to send email to customer), can I insert a new record into my OrderEmails collection after every Order create operation. in a pre or after hook.
Thanks.
Hi Yazilim, unfortunately it’s not possible to query across collections from a trigger. All server-side operations are run within the context of the collection.
However, I’d also recommend that in the specific case you mentioned (an Orders collection and an OrderEmails collection), you may actually want to combine these into a single collection. Unlike some other databases like SQL Server, there is no requirement that data in the collection has to be of the same type. Instead, it is often better to store heterogeneous data in a collection, perhaps with a field to indicate its type. This also makes the querying scenario a little easier.
Very good article better than the official documentation I must say. Is it possible to invoke an external RESTful API from within the server side code (triggers or stored procs?)