Almost all organisations rely on data, be it in the form of files or databases (SQL, Oracle…). The most challenging aspect of managing data for any organisation is high-availability and disaster recovery. Starting with the release of SQL Server 2012 (Enterprise Edition) Microsoft introduced “Always On Availability Groups”.
This powerful capability ensures your databases are synchronised through one or more replicas (SQL Servers).
While Azure offers an Infrastructure as a Service capability, the mechanisms used to setup many of the requirements for an Always On Availability Group are different to those in a traditional environment. From the assignment of IP addresses through to load balancing across listeners, special consideration needs to be taken in order to establish a functional SQL environment. In this blog I will discuss how to setup an Always On Availability Group in Microsoft Azure.
This blog assumes that you already have basic knowledge of Azure infrastructure services and that you have created your Azure subscription, and configured the Resource Group, Storage account, VNET, and subnets.
It also assumes that you have basic SQL knowledge and have established your Domain Controller running on Windows Server 2012 R2.
Prerequisites:
- 1x Domain Controller
- 1x File Server (Used for file share witness)
- 2x DS3_v2 servers for installation of SQL Server 2014 Enterprise Edition
Part 1 – Preparing your environment
Step 1 – Availability Set
Before deploying a SQL server VM in Azure, you will need to create an availability set (this is to be used with the Azure Internal Load Balancer (ILB) at a later stage and also to protect your VMs from a single point of failure.
Note: It is important to create an Availability Set before provisioning a VM. In AzureRM, adding a VM (after it’s been created) to an Availability Set is not supported as of this writing.
What is an Availability Set?
Availability Sets are a set of racks, and racks of servers. Just like a traditional datacentre. When you place two or more VMs in an availability set, the VMs will be deployed in two different racks. A rack usually consists of power equipment, network equipment, etc.
Why is this important?
Microsoft from time to time performs planned maintenance for Azure, although there’s no direct impact on VMs, some VMs might need to be rebooted to complete the update. Also too, Microsoft always takes the possibility of a risk that a rack might go down.
More on Availability Sets and best practice could be found here.
Create an Availability Set
In Azure’s sidebar click on “New” and search for “Availability Set”, Create your availability set with a name that makes sense to you, e.g. AZ-AS-SQL
- AZ = Azure
- AS = Availability Set
- SQL = Defining the purpose
Step 2 – Provisioning VMs
In Azure, select your defined Resource Group, and click “Add”, choose Windows, and then select Windows Server 2012R2.
For a production, it is best to choose a DS3 type VM, for larger environments, choose F8. Also too, choose your disks to be Premium disk. For dev/test workloads, you could go with Standard disks rather than Premium.
While creating your SQL VM, choose the availability set you have created in step 1.
If you need more than 1024Gb (1TB) of disk, you would need to create multiple disks, and create a storage pool and a VHD in Windows Server 2012R2 to combine those disks into one, since Azure gives you a maximum of 1024GB of disk space. Combining disks will also give you a better performance and a higher IOPS.
When creating disks, you would need to configure them as follow – Assuming you’re creating one disk for each SQL service.
Note: Name your disks in a way you’d recognise. Should you delete the VM, you might need to re-attach the disks to a new VM. When deleting a VM, your disks remain and are not deleted with the VM (unless the storage account or resource group is deleted). A good example for naming a disk might be “VMName-Data01”.
| Disk Type | Purpose | Host Cashing |
| Premium | SQL Binaries | None |
| Premium | TempDB | Read |
| Premium | Data | Read |
| Premium | Transaction | None |
| Premium | Backup | None |
You could choose a “Standard” Disk type for backup.
Your disks should have the same letters assigned to them, in both SQL Servers.
Once your SQL Server has been created, join it to the domain.
Part 2 – SQL Server – Installation
Prerequisite:
.NET Framework 3.5
[code language=”PowerShell”]Install-WindowsFeature Net-Framework-Core [/code]
After the SQL Server VM has joined the domain, start with the installation of SQL Server 2014 Enterprise.
Note: It is recommended to create gMSA accounts for both SQL Server Agent service and SQL Server Database Engine service.
These accounts should have “Log on as a Service” permissions. This could be standardised through the use of Group Policies.
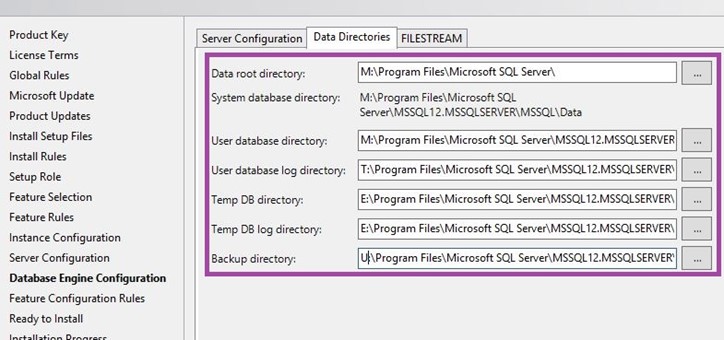
A quick note on how I have provisioned my SQL Server disks.
I have combined SQL Binaries and TempDB in one disk.
- SQL Binaries and TempDB = E
- Data = M
- Transaction = T
- Backup = U
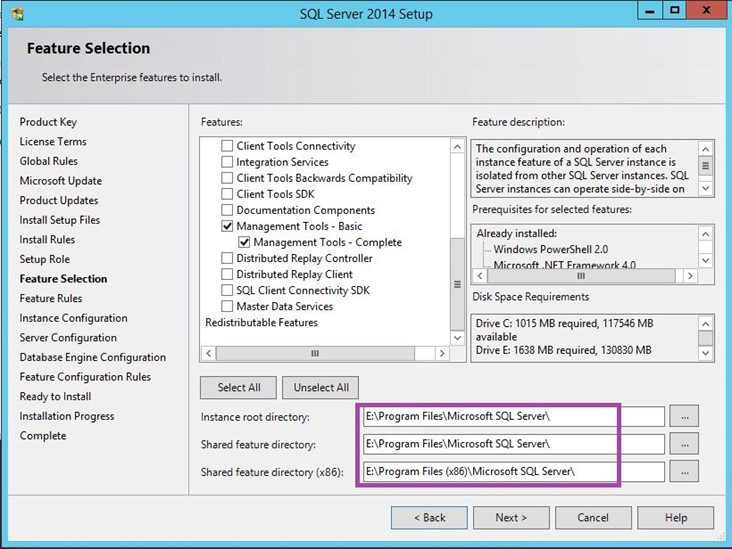
Feature Selection
Each environment is different and may require different features to be installed.
In this scenario, we only require:
- Database Engine Services
- SQL Server Replication
-
Management Tools – Basic
- Management Tools – Complete
Drive and Path selections
Part 3 – Failover Cluster
Before we start installing the Failover Clustering, we need to first choose a server in which will host our File Share Witness. This will be set up in a later stage though.
Why a file share witness and not a disk?
Windows Server 2008 and higher provided the option to use a file share witness as a quorum configuration. In traditional clustering you would have needed a shared disk, configured through the clustering setup. In this case you don’t need a shared disk to create a Windows Server Failover Cluster for Always On Availability Groups.
On the Server that you have deployed your SQL Servers, open PowerShell and install the “Failover Clustering” feature. (You could also start with this step prior to installing SQL Server).
Failover Cluster – Installation and Configuration
After launching the Failover Cluster Manager (console), right click on Failover Cluster Manager and choose “Create Cluster”
[code language=”PowerShell”]#Creating a cluster
Install-WindowsFeature –Name Failover-Clustering –IncludeManagementTools
#The following cmdlet runs all cluster validation tests on computers that are named Test-AZ-DB-01 and Test-AZ-DB-02.
Test-Cluster –Node Test-AZ-DB-01, Test-AZ-DB-02
#The Test-Cluster cmdlet outputs the results to a log file in the current working directory, for example C:\Users\username\AppData\Local\Temp.
#The following cmdlet creates the failover cluster without adding eligible storage to the failover cluster, as eligible storage isn’t required
New-Cluster –Name AZ-WSFC-01 –Node Test-AZ-DB-01, Test-AZ-DB-02 –StaticAddress 192.168.162.12 -NoStorage
#The following cmdlet creates a cluster that is named AZ-WSFC-01 in the Cluster OU of the domain.
New-Cluster -Name CN=AZ-WSFC-01,OU=SQL,DC=test,DC=local -Node Test-AZ-DB-01, Test-AZ-DB-02
#Creating a FileShareWitness – Make sure the folder is already created, and permissions are assigned.
Set-ClusterQuorum –FileShareWitness \\FileServer\ClusterShareWitness[/code]
Or, if you prefer, follow the GUI:
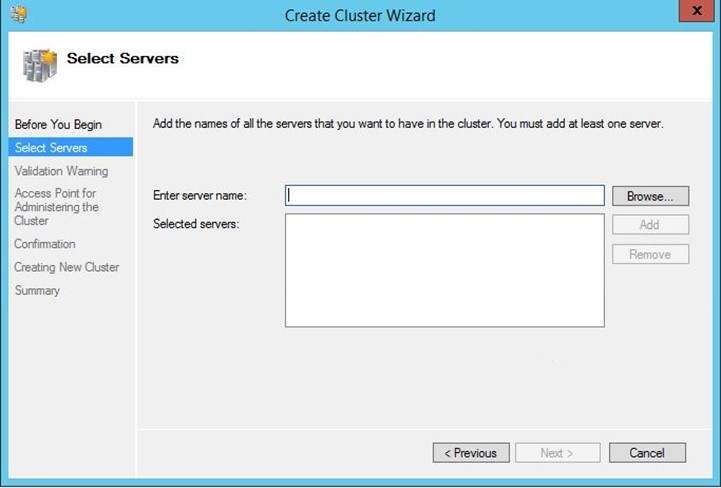
Enter your “Nodes” – These are your SQL servers.
Run your validation in the next step – It is all right for the Validation to give you warning, since we’re not specifying any storage disks.
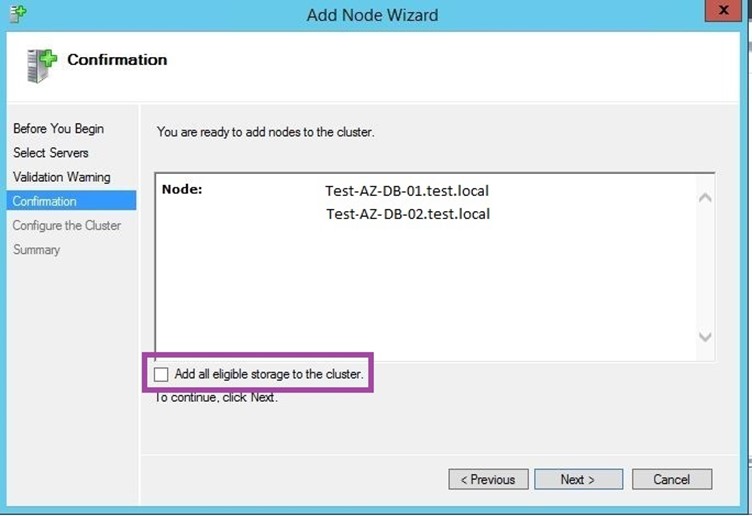
After adding your servers in the above steps, you should see them in the “Confirmation” window.
Uncheck the “Add all eligible storage to the cluster”.
In the next screen, you will specify the name of your Cluster Server, e.g: AZ-WSFC-01
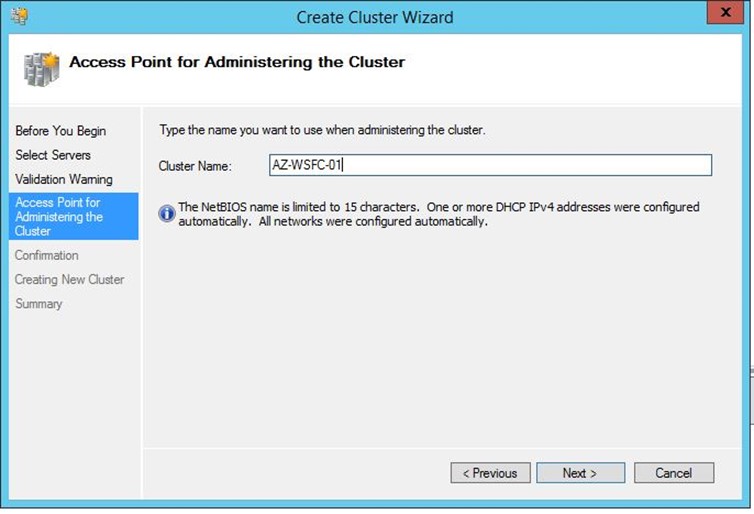
Click next, until completion.
Once your cluster is created, you need to check the IP Address, since a DHCP address has been allocated to the cluster, as this is different than using PowerShell
To do that,
- Click on your Cluster Server Name “AZ-WSFC-01”
- Scroll down to “Cluster Core Resources”
- Right-click the IP Address
- Select “Static IP Address”.
Remember our File Share Witness? It’s time to create the folder on the server which will host the File Share Witness.
Follow the steps, if you haven’t used PowerShell cmdlets above.
In my case, I am using the File Server as my File Share Witness.
- Create a folder in any drive you have available, call it “ClusterWitnessShare”.
- Share the folder with the cluster computer object. This is done through “Advanced Sharing permissions”.
- Confirm that the folder is shared, and firewall is allowing access should you have one.
Now that you have added the nodes, specified an IP Address, and configured your File Share Witness, it is time to add a Quorum for your failover cluster.
To do that through PowerShell
[code language=”PowerShell”]Set-ClusterQuorum –FileShareWitness \\FileServer\ClusterShareWitness[/code]
To do that through GUI
- Right click on your cluster name AZ-WSFC-01
- Click on “More Actions”
- Click on “Configure Cluster Quorum Settings”.
Follow these steps:
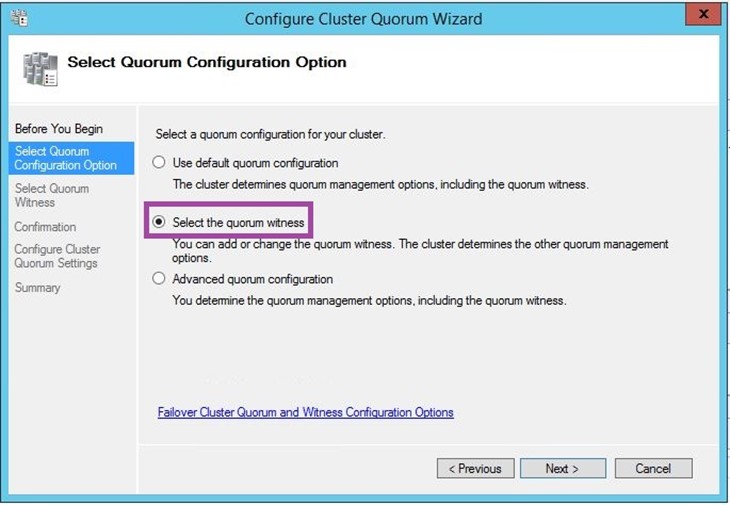
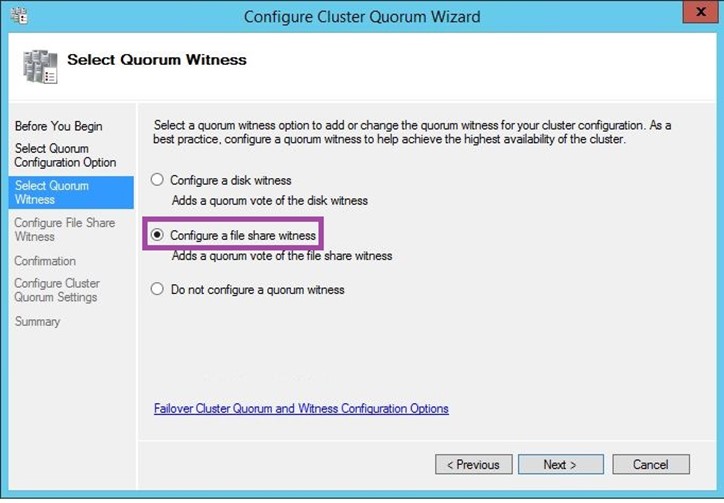
In the next step, you could click “Browse” and enter the name of your server hosting the “ClusterWitnessShare”, and the shared folder will appear.
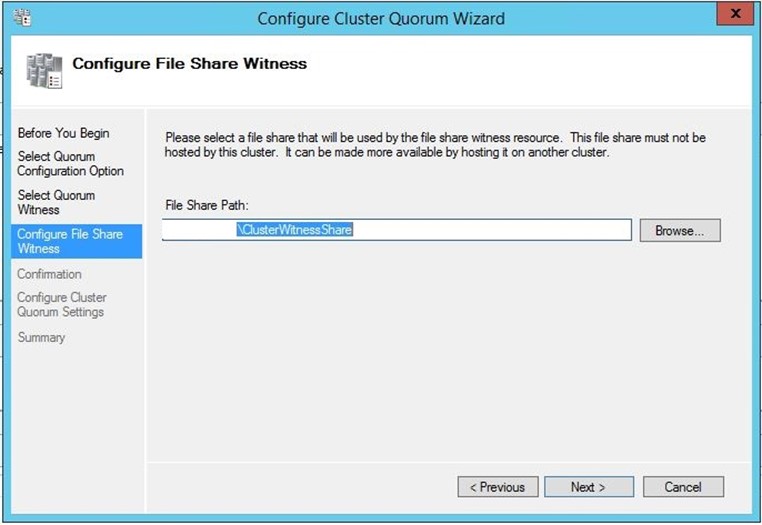
Continue clicking “next” until your Quorum is created.
No additional tasks are required for the Quorum after that.
Cluster and SQL Server Permissions
In order to be able to create a listener (in the next steps) you will need to make sure that the following permissions are set.
For the SQL Servers Computer Objects:
In Active Directory, select “Advanced Features”. Go to the OU in which your SQL Servers reside, this is where the cluster computer object will be.
- Right-click on the Cluster Computer Object
- Security
- Add your SQL Servers – Alternatively, you could create a security group in which your SQL Servers are a member of.
-
Assign the following permissions – For each server, if you didn’t create a security group:
| Allow Permissions |
| Read |
| Allowed To Authenticate |
| Change Password |
| Receive As |
| Reset Password |
| Send As |
| Validate write To DNS Host Name |
| Validate Write To Service Principle Name |
| Read Account Restrictions |
| Write Account Restrictions |
| Read DNS Host Name Attributes |
| Read MS-TS-GatewayAccess |
| Read Personal Information |
| Read Public Information |
For the WSFC Computer Object:
- In Active Directory go to Users
- Click on Domain Admins
- Add the WSFC computer objects (this should automatically be removed once a listener is created. You may have to re-add it if you’re creating more than one listener).
If this permission isn’t set, your listener will fail to be created in AD and DNS records. And as a result your Availability Group will not come online. More on this below.
Part 4 – Availability Groups
What is an Availability Group?
Microsoft describes an Availability Group as follows: An availability group supports a failover environment for a discrete set of user databases, known as availability databases, that fail over together. An availability group supports a set of primary databases and one to eight sets of corresponding secondary databases. Secondary databases are not backups. Continue to back up your databases and their transaction logs on a regular basis.
Documentation for Availability Groups is located here. It’s also worth checking the previous sections of the document, specifically the pre-requisites and restrictions for an Always On Availability Group. Although it is a fairly and straightforward task, you need to decide how data is going to be committed across your SQL instances (asynchronous or synchronous), and that your Databases have no data loss in the case of a disaster.
Creating an Always On Availability Group.
Now that you have your Failover Cluster ready, you will need to launch the SQL Server Configuration Manager. This is where you first have to “turn on” the Always On Availability Group.
To do this through PowerShell:
First run the following cmdlet to enable AlwaysOn on all the nodes in the cluster:
[code language=”PowerShell”]foreach ($node in Get-ClusterNode) {Enable-SqlAlwaysOn -ServerInstance $node -Force} [/code]
To Enable AlwaysOn on each server one by one, then run the following cmdlet:
[code language=”PowerShell”]Enable-SqlAlwaysOn -ServerInstance MSSQLSERVER -Force [/code]
[code language=”PowerShell”]
[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.Smo") |
Out-Null
[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoExtended") |
Out-Null
$SqlServerPrimName = "SQL01"
$SqlServerSecName = "SQL02"
$SqlAgName = "TestAg"
$SqlAgDatabase = "TestDB"
$HadrEndpointName = "HadrEndpoint"
$HadrEndpointPort = 5022
$BackupDirectory = "\\SQL01\Backup"
$SqlServerPrim = New-Object Microsoft.SqlServer.Management.Smo.Server($SqlServerPrimName)
$SqlServerSec = New-Object Microsoft.SqlServer.Management.Smo.Server($SqlServerSecName)
#Backup the database on the primary replica/server (full database backup)
$DbBackup = New-Object Microsoft.SqlServer.Management.Smo.Backup
$DbBackup.Database = $SqlAgDatabase
$DbBackup.Action = [Microsoft.SqlServer.Management.Smo.BackupActionType]::Database
$DbBackup.Initialize = $true
$DbBackup.Devices.AddDevice(“$BackupDirectory\$($SqlAgDatabase)_AgSetup_full.bak”,
[Microsoft.SqlServer.Management.Smo.DeviceType]::File)
$DbBackup.SqlBackup($SqlServerPrim)
#Backup the database (transaction log backup)
$DbBackup = New-Object Microsoft.SqlServer.Management.Smo.Backup
$DbBackup.Database = $SqlAgDatabase
$DbBackup.Action = [Microsoft.SqlServer.Management.Smo.BackupActionType]::Log
$DbBackup.Initialize = $true
$DbBackup.Devices.AddDevice(“$BackupDirectory\$($SqlAgDatabase)_AgSetup_log.trn”,
[Microsoft.SqlServer.Management.Smo.DeviceType]::File)
$DbBackup.SqlBackup($SqlServerPrim)
#Restore the database on the secondary replica/server (full database restore)
$DbRestore = New-Object Microsoft.SqlServer.Management.Smo.Restore
$DbRestore.Database = $SqlAgDatabase
$DbRestore.Action = [Microsoft.SqlServer.Management.Smo.RestoreActionType]::Database
$DbRestore.Devices.AddDevice(“$BackupDirectory\$($SqlAgDatabase)_AgSetup_full.bak”,
[Microsoft.SqlServer.Management.Smo.DeviceType]::File)
$DbRestore.NoRecovery = $true
$DbRestore.SqlRestore($SqlServerSec)
#Restore the database on the secondary replica/server (transaction log restore)
$DbRestore = New-Object Microsoft.SqlServer.Management.Smo.Restore
$DbRestore.Database = $SqlAgDatabase
$DbRestore.Action = [Microsoft.SqlServer.Management.Smo.RestoreActionType]::Log
$DbRestore.Devices.AddDevice(“$BackupDirectory\$($SqlAgDatabase)_AgSetup_log.trn”,
[Microsoft.SqlServer.Management.Smo.DeviceType]::File)
$DbRestore.NoRecovery = $true
$DbRestore.SqlRestore($SqlServerSec)
#Create the endpoint on the primary replica
$EndpointPrim = $SqlServerPrim.Endpoints |
Where-Object {$_.EndpointType -eq [Microsoft.SqlServer.Management.Smo.EndpointType]::DatabaseMirroring}
if(!$EndpointPrim) {
$EndpointPrim = New-Object Microsoft.SqlServer.Management.Smo.Endpoint($SqlServerPrim, $HadrEndpointName)
$EndpointPrim.EndpointType = [Microsoft.SqlServer.Management.Smo.EndpointType]::DatabaseMirroring
$EndpointPrim.ProtocolType = [Microsoft.SqlServer.Management.Smo.ProtocolType]::Tcp
$EndpointPrim.Protocol.Tcp.ListenerPort = $HadrEndpointPort
$EndpointPrim.Payload.DatabaseMirroring.ServerMirroringRole = [Microsoft.SqlServer.Management.Smo.ServerMirroringRole]::All
$EndpointPrim.Payload.DatabaseMirroring.EndpointEncryption = [Microsoft.SqlServer.Management.Smo.EndpointEncryption]::Required
$EndpointPrim.Payload.DatabaseMirroring.EndpointEncryptionAlgorithm = [Microsoft.SqlServer.Management.Smo.EndpointEncryptionAlgorithm]::Aes
$EndpointPrim.Create()
$EndpointPrim.Start()
}
#Create the endpoint on the secondary replica
$EndpointSec = $SqlServerSec.Endpoints |
Where-Object {$_.EndpointType -eq [Microsoft.SqlServer.Management.Smo.EndpointType]::DatabaseMirroring}
if(!$EndpointSec) {
$EndpointSec = New-Object Microsoft.SqlServer.Management.Smo.Endpoint($SqlServerSec, $HadrEndpointName)
$EndpointSec.EndpointType = [Microsoft.SqlServer.Management.Smo.EndpointType]::DatabaseMirroring
$EndpointSec.ProtocolType = [Microsoft.SqlServer.Management.Smo.ProtocolType]::Tcp
$EndpointSec.Protocol.Tcp.ListenerPort = $HadrEndpointPort
$EndpointSec.Payload.DatabaseMirroring.ServerMirroringRole = [Microsoft.SqlServer.Management.Smo.ServerMirroringRole]::All
$EndpointSec.Payload.DatabaseMirroring.EndpointEncryption = [Microsoft.SqlServer.Management.Smo.EndpointEncryption]::Required
$EndpointSec.Payload.DatabaseMirroring.EndpointEncryptionAlgorithm = [Microsoft.SqlServer.Management.Smo.EndpointEncryptionAlgorithm]::Aes
$EndpointSec.Create()
$EndpointSec.Start()
}
$AvailabilityGroup = New-Object Microsoft.SqlServer.Management.Smo.AvailabilityGroup($SqlServerPrim, $SqlAgName)
#Create the primary replica object
$PrimaryReplica = New-Object Microsoft.SqlServer.Management.Smo.AvailabilityReplica($AvailabilityGroup, $SqlServerPrimName)
$PrimaryReplica.EndpointUrl = "TCP://$($SqlServerPrim.NetName):$($EndpointPrim.Protocol.Tcp.ListenerPort)"
$PrimaryReplica.FailoverMode = [Microsoft.SqlServer.Management.Smo.AvailabilityReplicaFailoverMode]::Automatic
$PrimaryReplica.AvailabilityMode = [Microsoft.SqlServer.Management.Smo.AvailabilityReplicaAvailabilityMode]::SynchronousCommit
$AvailabilityGroup.AvailabilityReplicas.Add($PrimaryReplica)
#Create the secondary replica object
$SecondaryReplica = New-Object Microsoft.SqlServer.Management.Smo.AvailabilityReplica($AvailabilityGroup, $SqlServerSecName)
$SecondaryReplica.EndpointUrl = "TCP://$($SqlServerSec.NetName):$($EndpointSec.Protocol.Tcp.ListenerPort)"
$SecondaryReplica.FailoverMode = [Microsoft.SqlServer.Management.Smo.AvailabilityReplicaFailoverMode]::Automatic
$SecondaryReplica.AvailabilityMode = [Microsoft.SqlServer.Management.Smo.AvailabilityReplicaAvailabilityMode]::SynchronousCommit
$AvailabilityGroup.AvailabilityReplicas.Add($SecondaryReplica)
#Create the availability group database object
$AvailabilityDb = New-Object Microsoft.SqlServer.Management.Smo.AvailabilityDatabase($AvailabilityGroup, $SqlAgDatabase)
$AvailabilityGroup.AvailabilityDatabases.Add($AvailabilityDb)
#Create the availability group
$SqlServerPrim.AvailabilityGroups.Add($AvailabilityGroup)
$AvailabilityGroup.Create()
#Join the secondary replica to the AG, and join the database to the AG
$SqlServerSec.JoinAvailabilityGroup($SqlAgName)
$SqlServerSec.AvailabilityGroups[$SqlAgName].AvailabilityDatabases[$SqlAgDatabase].JoinAvailablityGroup()
[/code]
To use GUI, search for “SQL Server Configuration Manager”, and open it.
- Select the SQL Server Service, and then select the SQL Server Instance (if you have more than one instances, select the instance in which you’re configuring Always On Availability Group for).
- Right-click the SQL Server Instance (MSSQLSERVER in this case) and go to properties.
- Select the “Always On Availability Group” tab, and in there you should see the Failover Cluster Computer Name (created in previous step).
- Tick or select “Enable Always On Availability Group” and click “OK”.
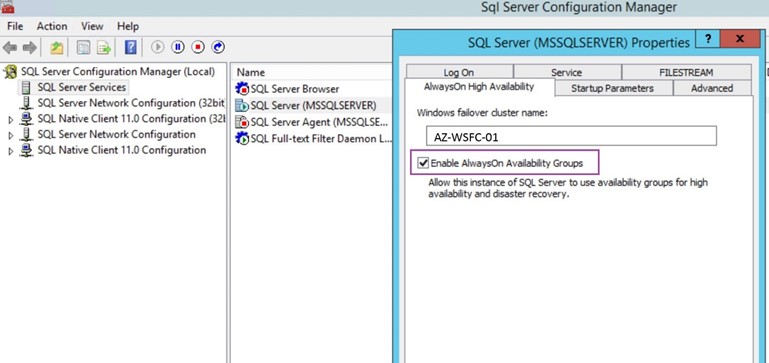
You will be prompted to restart the service for changes to be saved, restart the service of your instance (MSSQLSERVER).
Once the service has been restarted, navigate to “SQL Server Management Studio”, launch it and connect to your preferred database engine.
Prerequisite to create an Availability Group:
- A database. This could even be a test Database.
- Full back-up performed for the Database.
Creating an Availability Group:
-
Right-click on “Always On High Availability”
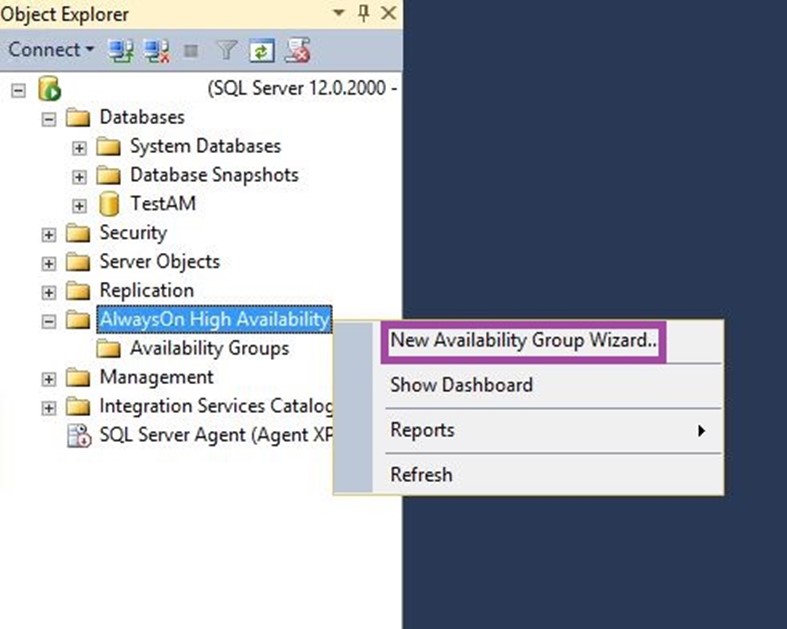
- Select ‘New Availability Group Wizard’
-
Name your Availability Group, e.g. AG01
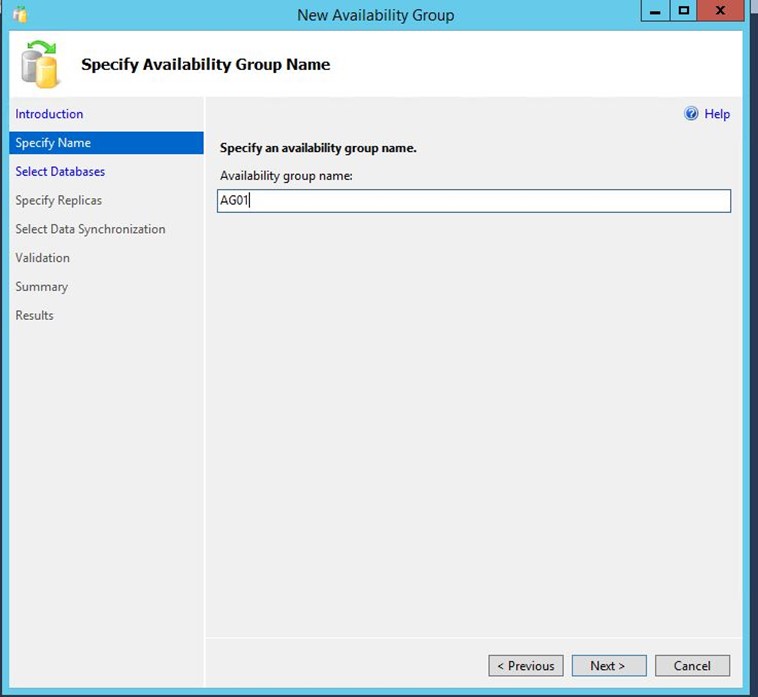
-
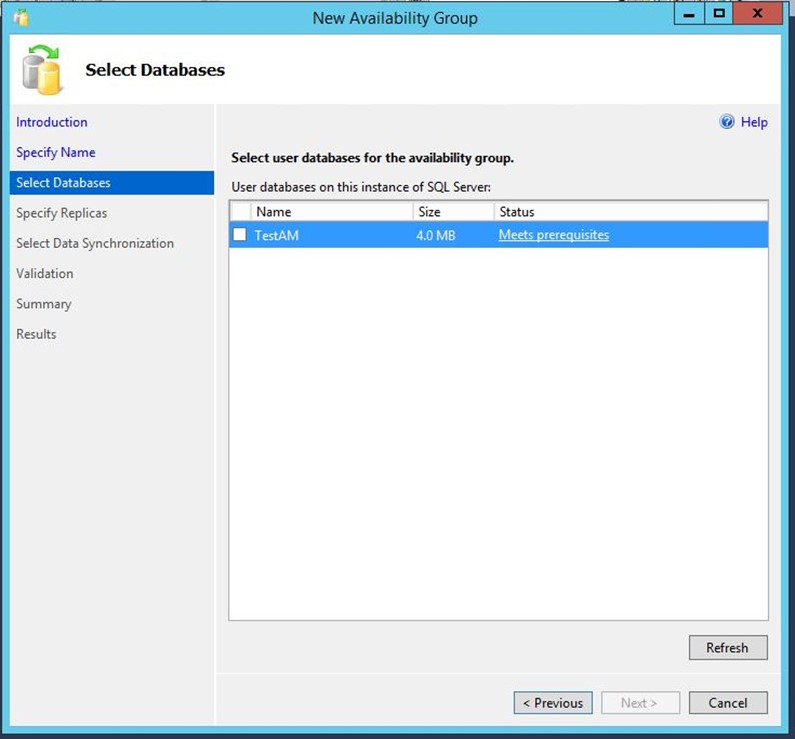
Select your DB.
-
Note: If your DB doesn’t meet the requirements, SQL will suggest an action, e.g. performing full back of the DB.
-
Specify your replicas.
Note: Do not configure a listener at this stage.
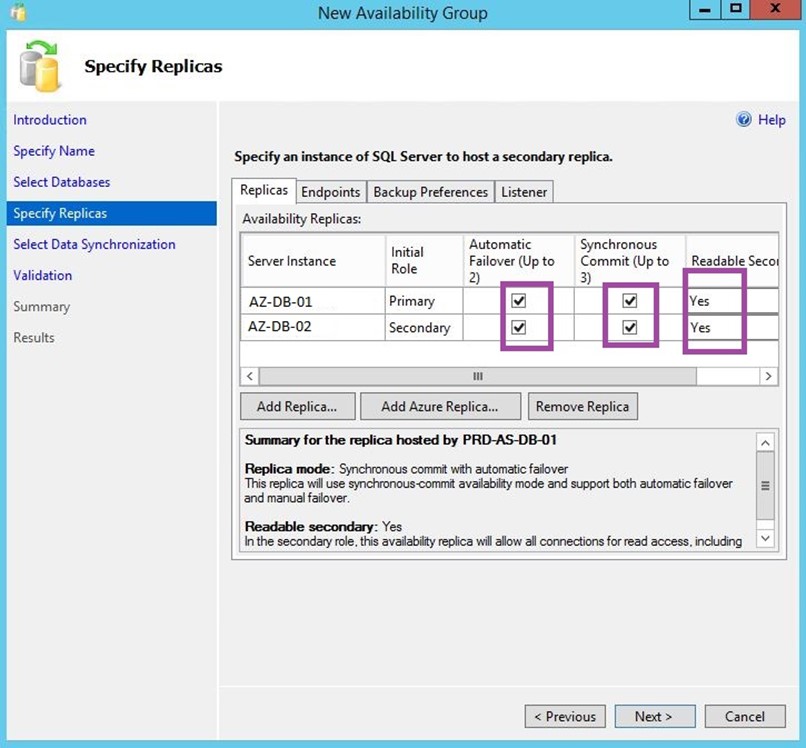
-
Select your Synchronization method.
Note: You could also select “Full”. Make sure however, you already have a shared network location accessible by your SQL servers.
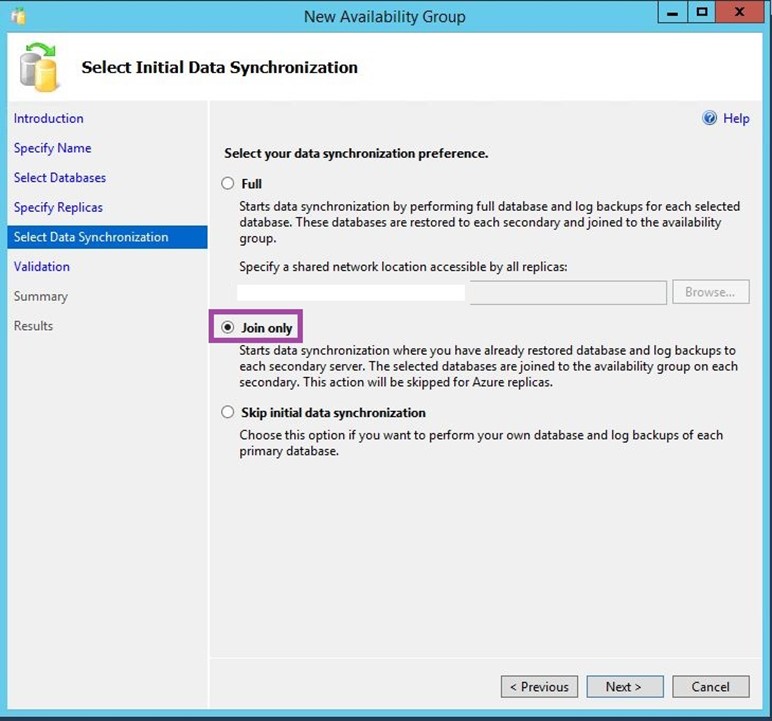
-
You will receive a warning in the validation section, that’s because we haven’t configured a listener. It will not prevent you from creating your availability group nevertheless.
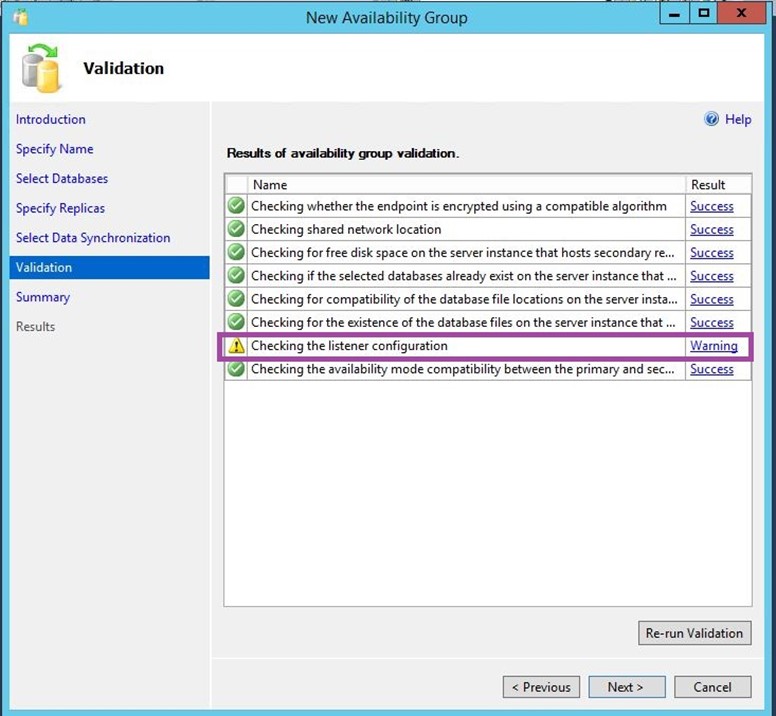
-
Once you click “Next” SQL will create the Availability Group with no issues.
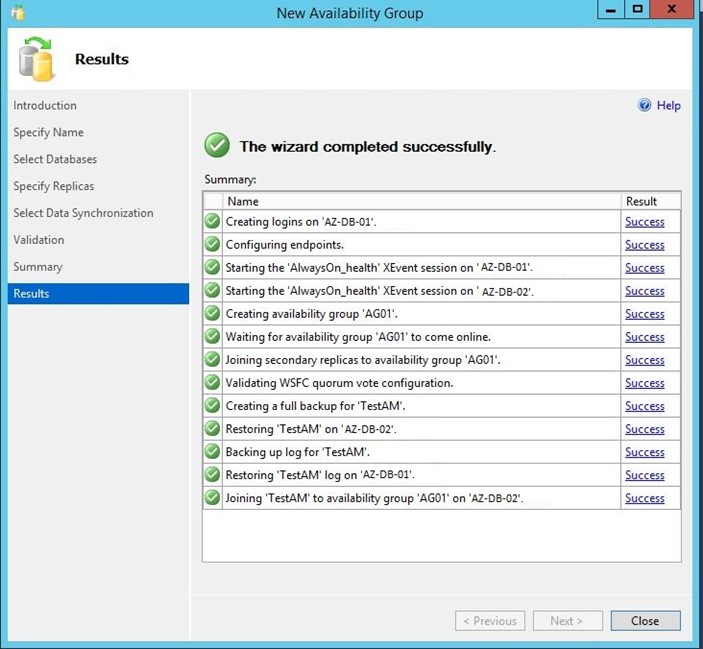
- Click “Close”.
Part 5 – Internal Load Balancer and creating the listener
The last step in getting a SQL Server Always On Availability Group working in Azure is where we will create and configure our Azure Load Balancer and create the listener.
Azure networking is different than on premise networking, and this is the main reason why we need to create an Azure Internal Load Balancer for our Availability Group Listener.
In Azure, create on “New” and search for “Load Balancer”, select the Load Balancer and click on Create.
Internal Load Balancer (ILB) configuration
In this section we will discuss best practice in configuring the ILB for your SQL Availability Listener.
| Setting | Field |
| Backend pool Name | SQLILB |
| SQLLBBE Availability set | AZ-AS-SQL |
| SQLLBBE Virtual machines | AZ-DB-01, AZ-DB-02 |
| SQLLBBE Used by | SQLAlwaysOnEndPointListener |
| Probe Name | SQLAlwaysOnEndPointProbe |
| Probe Protocol | TCP |
| Probe Port | 59999 – (You can use any unused port). |
| Probe Interval | 5 |
| Probe Unhealthy threshold | 2 |
| Probe Used by | SQLAlwaysOnEndPointListener |
| Load balancing rules Name | SQLAlwaysOnEndPointListener |
| Load balancing rules Protocol | TCP |
| Load balancing rules Port | 1433 – Because this is the SQL Server default port. |
| Load balancing rules Port | 1433 – Because this is the SQL Server default port. |
| Load balancing rules Backend Port | 1433 |
| Load balancing rules Probe | SQLAlwaysOnEndPointProbe |
| Load balancing rules Session Persistence | None |
| Load balancing rules Idle Timeout | 4 |
| Load balancing rules Floating IP (direct server return) | Enabled |
Failover Cluster Configuration
The first step you need to here is to create a resource Client Access Point.
To do that through PowerShell:
[code language=”PowerShell”]
Add-ClusterResource –Name LSTR-01 –ResourceType IP Address –Group Cluster Group [/code]
To do that through GUI:
- Open the WSFC Manager
- Expand the cluster name
- Click on “Roles”
- Right click on your role (availability group name)
- Click “Add Resource”
- Choose “Client Access Point”
The “Client Access Point” is what will be your listener object, e.g. LSTR-01, as used in this example.
- Click “Next” and then click “Finish”.
Do not bring the listener or resource online at this point.
In Failover Cluster Manager, note the name of the cluster network. To determine the cluster network name in Failover Cluster Manager, click Networks in the left pane.
Note: You will use this name in the $ClusterNetworkName variable in the PowerShell script.
Click the Resources tab, then expand the Client Access Point you just created. Right-click the IP resource and click properties. Note the name of the IP address (Note that you can enter any value you like).
Note: You will use this name in the $IPResourceName variable in the PowerShell script.
Under IP Address click “Static IP Address” and set the static IP address to the same address that you used on the Azure Portal for “SQLILB” load balancer. Enable NetBIOS for this address and click “OK”.
Note: You will also use this same IP address in the $ILBIP variable in the PowerShell script.
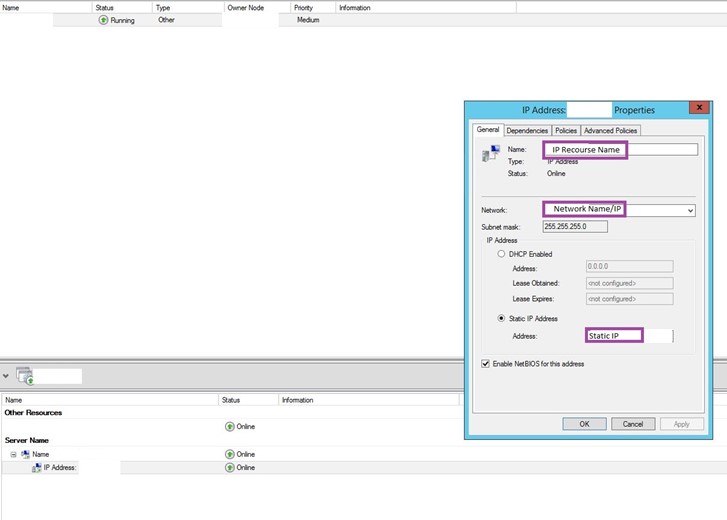
On the cluster node that currently hosts the primary replica, open an elevated PowerShell ISE and paste the following commands into a new script – Don’t forget to change the variables.
[code language=”PowerShell”]$ClusterNetworkName = "SQL Failover Cluster Network" # the cluster network name (Use Get-ClusterNetwork on Windows Server 2012 of higher to find the name)
$IPResourceName = "SQLAGLSTR" # the IP Address resource name
$ILBIP = "172.19.2.10" # the IP Address of the Internal Load Balancer (ILB). This is the static IP address for the load balancer you configured in the Azure portal.
Import-Module FailoverClusters
Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{"Address"="$ILBIP";"ProbePort"="59999";"SubnetMask"="255.255.255.0";"Network"="$ClusterNetworkName";"EnableDhcp"=0} [/code]
Once the script has run successfully, you will need to:
- Edit some dependencies for the role to come online,
- Make sure your listener is registered in the OU (computer objects gets created in the same OU your SQL servers and Cluster are),
- And configure the listener port in SQL.
To do that, follow the steps below:
Navigate back to Failover Cluster Manager. Expand Roles and then highlight your Availability Group (your role). On the Resources tab, right-click the listener name and click Properties.
Click the Dependencies tab. If there are multiple resources listed, verify that the IP addresses have OR, not AND, dependencies.
Note If you changed the name of your IP Address, to something like “lstrIP”, that’s what you will see and need to set in the dependencies.
Right-click the listener name and click Bring Online.
Once the listener is online, from the Resources tab, right-click the availability group and click Properties.
Create a dependency on the listener name resource (The computer object – not the IP address resources name). You may have to bring the availability group offline to change the dependency. Once the dependency is changed, click “OK” then bring online.
Note: In this situation, your primary replica might have changed, failover back to your primary replica before changing the port.
Launch SQL Server Management Studio and connect to the primary replica.
Navigate to Always On High Availability > Availability Groups > Availability Group Listeners.
You should now see the listener name that you created in Failover Cluster Manager. Right-click the listener name and click Properties.
In the Port box, specify the port number for the availability group listener by using the $EndpointPort you used earlier (1433 was the default), then click “OK”.
Test the connection to the listener
You can do that through telnet,
Telnet lstr-01 1433
Or through PowerShell
[code language=”PowerShell”]Move-ClusterGroup Cluster Group –node Test-AZ-DB-02[/code]
Thanks for reading, and I hope you found this useful. And please feel free to add your comments below.
Are gMSA accounts fully supported with SQL Server Cluster?
So far based on the MS documentation https://msdn.microsoft.com/en-us/library/ms143504(v=sql.120).aspx its not supported.
Hi Thomas, thank you for your comment.
Although Microsoft does state that gMSA is not supported, there’s confusion around this.
This blog assumes you’re installing a SQL Server Instance, then add it to a cluster. And not installing a SQL Server Failover Cluster Node which will create a Failover Cluster Instance (FCI).
Also too notice, that in the description Microsoft mentioned that a gMSA is assigned to a single computer, in our case we assign the gMSA to multiple computers for running the same SQL services on a Windows Server 2012R2. gMSA are not used for the failover cluster service.
Another note is that this has since been dropped with SQL Server 2016, nevertheless, to use gMSA you would still have to use a Windows Server 2012R2.
I hope this clarifies it for you, but should you have any questions, please don’t hesitate to reply back.
Hi,
Can we use same port 1433 in ILB config for another availability group in the same set?
My ops team says you can’t. but some of the blogs/online doc says you can.It will be helpful if you can provide some more details so that I can take it to our OPS team.
Thanks,
Jayesh
How is this static address obtained? (otherwise excellent write up so far)
New-Cluster –Name AZ-WSFC-01 –Node Test-AZ-DB-01, Test-AZ-DB-02 –StaticAddress 192.168.162.12