
S
This blog will cover how to use SageMaker, and I’ve included the code from my GitHub, https://github.com/Steve–Hunter/DeepLens-Safety-Helmet.
1 What is AWS SageMaker?
AWS (Amazon Web Services) SageMaker is “a fully managed machine learning service. With Amazon SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment.” (https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html). In other words, SageMaker gives you a one-stop-shop to get your Deep Learning models going, in a relatively friction-less way.
Amazon have tried hard to deliver a service that appeals to the life-cycle for developing models, which are the results of training. It enables Deep Learning to complete the virtuous circle of:
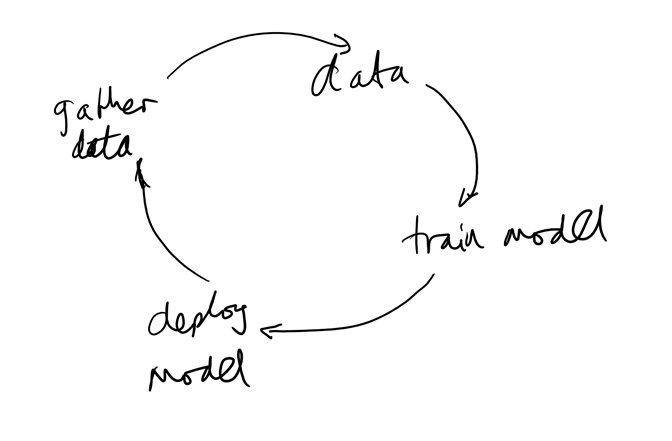
Data can cover text, numeric, images, video – the idea is that the model gets ‘smarter’ as it learns more of the exceptions and relationships in being given more data.
SageMaker provides Jupyter Notebooks as a way to develop models; if you are unfamiliar, think of Microsoft OneNote with code snippets, you can run (and re-run) a snippet at a time, and intersperse with images, commentary, test runs. The most popular coding language is Python (which is in the name of Jupyter).
2 AI / ML / DL ?
I see the phrases AI (Artificial Intelligence), Machine Learning (ML) and Deep Learning used inter-changeably, this diagram shows the relationship:
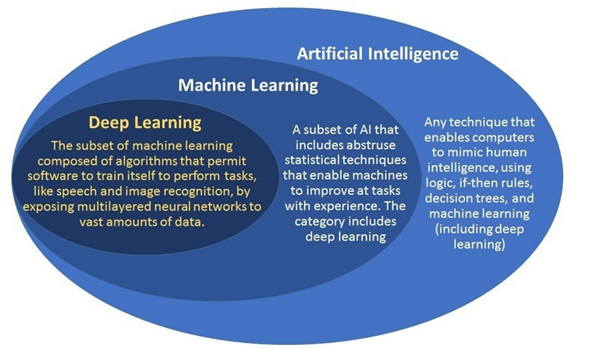
So I see AI encompassing most things not yet possible (e.g. Hollywood ‘killer robots’); Deep Learning has attracted attention, as it permits “software to train itself”; this is contrary to all previous software, which required a programmer to specifically tell the machine what to do. What makes this hard is that it is very difficult to foresee everything that could come up, and almost impossible to code for exception from ‘the real world’. An example of this is machine vision, where conventional ‘rule-based’ programming logic can’t be applied, or if you try, only works in very limited circumstances.
This post will cover the data and training of a custom model to identify people wearing safety helmets (like those worn on a construction site), and a future post will show how to load this model into an AWS DeepLens (please see Sam Zakkour’s post on this site). A use case for this would be getting something like a DeepLens to identify workers at a construction site that aren’t wearing helmets.
3 Steps in the project
This model will use a ‘classification’ approach, and only have to decide between people wearing helmets, and those that aren’t.
The project has 4 steps:
- Get some images of people wearing and not wearing helmets
- Store images in a format suitable for Deep Learning
- Fine tune an existing model
- Test it out!
3.1 Get some images of people wearing and not wearing helmets
The hunger for data to feed Deep Learning models has led to a number of online resources that can supply data. A popular one is Imagenet (http://www.image-net.org/), with over 14 million images in over 21,000 categories. If you search for ‘hard hat’ (a.k.a ‘safety helmet’) in Imagenet:
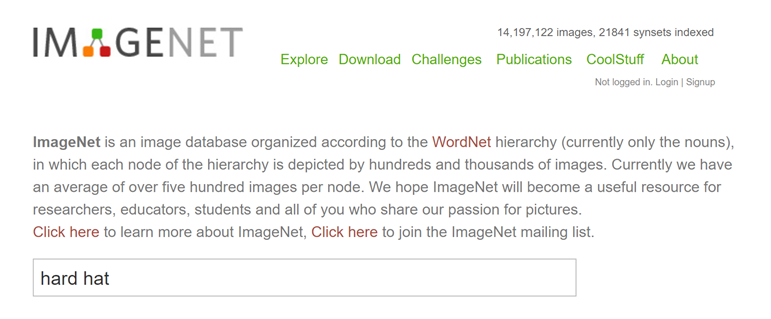
Your query returns:

The ‘Synset’ is a kind of category in Imagenet, and covers the inevitable synonyms such as ‘hard hat’, ‘tin hat’ and ‘safety hat’.
When you expand this Synset, you get all the images; we need the parameter in the URL that uniquely identifies these images (the ‘WordNet ID’) to download them:
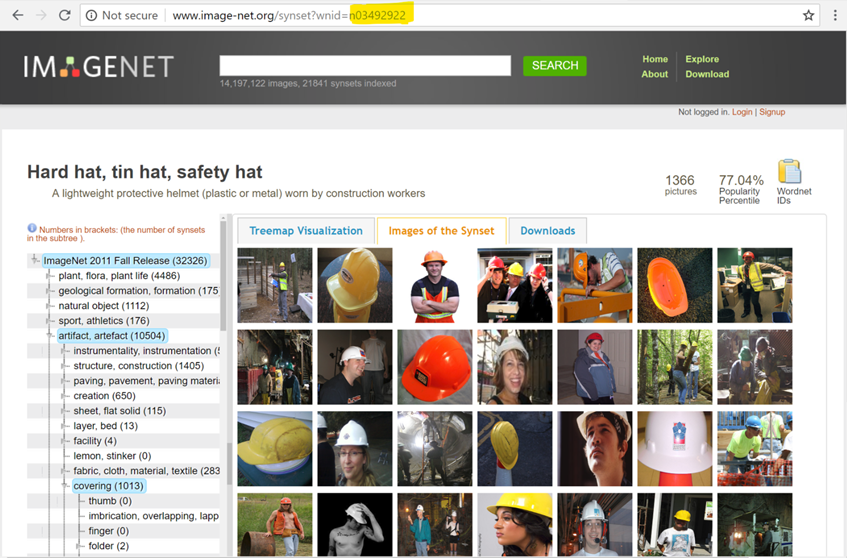
Repeat this for images of ‘people’.
Once you have the ‘WordNet ID’ you can use this to download the images. I’ve put the code from my Jupyter Notebook here if you want to try it yourself https://github.com/Steve–Hunter/DeepLens-Safety-Helmet/blob/master/1.%20Download%20ImageNet%20images%20by%20Wordnet%20ID.ipynb
I added a few extras in my code to:
- Count of images and reporting
- Added continue on bad image (poisoned my .rec image file!)
- Parameterise the root folder and class for images
This saves the images to the SageMaker server in AWS, where they are picked up by the next stage …
3.2 Store images in a format suitable for Deep Learning
It would be nice if we could just feed in the images as JPEGs, but most image processing frameworks require the images to be pre-processed, mainly for performance reasons (disk IO). AWS uses MXNet a lot, and so that’s the format I used, ‘ImageRecord format or recordIO. You can read more about it here https://gluon-cv.mxnet.io/build/examples_datasets/recordio.html, and the Jupyter Notebook is here https://github.com/Steve–Hunter/DeepLens-Safety-Helmet/blob/master/2.%20Store%20images%20into%20binary%20recordIO%20format%20for%20MXNEt.ipynb .
The utility to create the ImageRecord format also splits the images into
- a set of training and testing images
-
images that show wearing and not wearing helmets (the two categories we are interested in)
It’s best practice to train on a set of images, but test on another, in a ratio of around 70:30. This avoid the curse of deep learning of ‘over-fitting’ where the model hasn’t really learned ‘in general’ what people wearing safety helmets look like, only the ones it has seen already. This is the really cool part of deep learning, it really does learn, and can tell from an unseen image if there is a person(s) wearing a safety helmet!
The two ImageRecord files for training and testing are stored in SageMaker, for the next step …
3.3 Fine tune an existing model
One of my favourite saying is by Isaac Newton “If I have seen further it is by standing on the shoulders of Giants.”, and this applies to Deep Learning, in this case the ‘Giants’ are Google, Microsoft etc, and ‘standing on’ is the open source movement. You could train your model on all 14 million images in Imagenet, taking weeks and immense amount of compute power (which only Google/Microsoft can afford, but generously open source the trained models), but a neat trick in deep learning is to take an existing model that has been trained, and ‘re-purpose’ it for what you want. There may not be a pre-trained model for the images you want to identify, but you can find something close enough, and train it on just the images you want.
There are so many pre-trained models, the MXNet framework refers to them as a ‘model zoo’, the one I used is called ‘Squeezenet’ – there are competitions to find the model that can perform best, and Squeezenet gives good results, and is small enough to load onto a small device like a DeepLens.
So the trick is to start with something that looks like what we are trying to classify; Squeezenet has two existing categories for helmets, ‘Crash helmet’ and ‘Football helmet’.
When you use the model ‘as is’, it does not perform well, and gets things wrong – telling it to look for ‘Crash Helmets’ in these images, it thinks it can ‘see them’ – there are two sets of numbers below which each represent the probability of the corresponding images having helmets in them. Both numbers are a percentage and the first of the number being the prediction of a helmet, the second there not being a helmet.
!

Taking ‘Crash helmet’ as the starting point, and re-trained (also called ‘fine tuning’ or ‘transfer learning’) the last part of the model (the purple one on the far right), to learn what safety helmets look like.
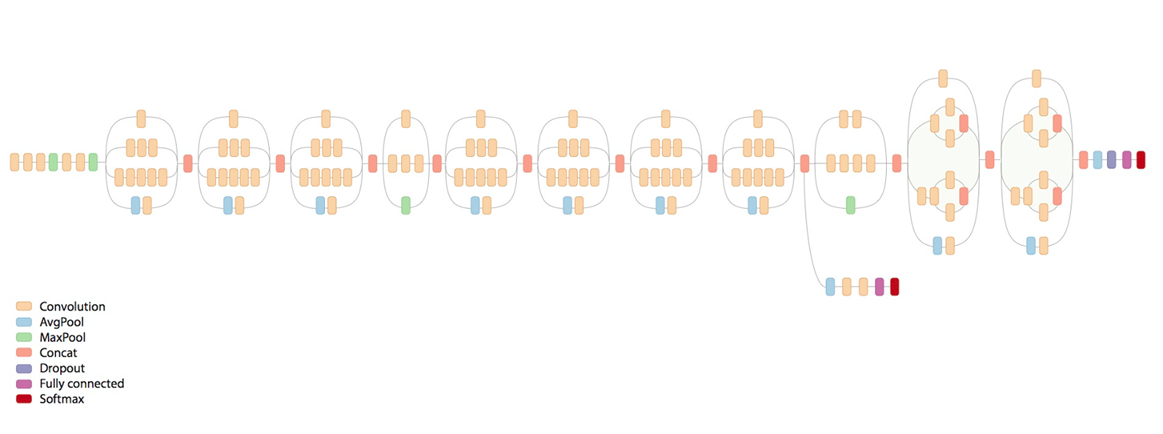
The training took about an hour, on an Amazon ml.t2.medium instance (free tier) and I picked the ‘best’ accuracy, you can see the code and runs here: https://github.com/Steve–Hunter/DeepLens-Safety-Helmet/blob/master/3.%20Fine%20tune%20existing%20model.ipynb
3.4 Test it out!
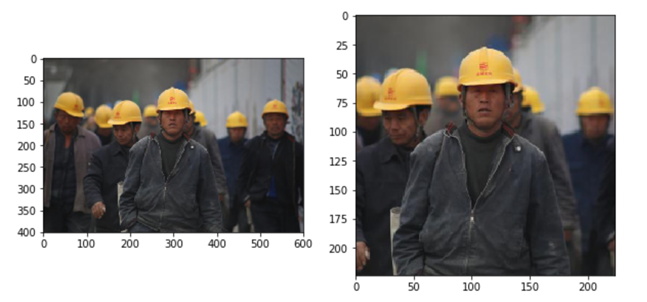
After training things improve a lot – in the first image below, the model is now 96% certain it can see safety helmets, and in the second 98% certain it is not.
What still ‘blows my mind’ is that there are multiple people in the image – the training set contained individuals, groups, different lighting and helmet colours – imagine trying to ‘code’ for this in a conventional way! But the model has learned the ‘helmet-ness’ of the images!

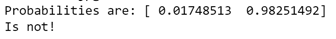

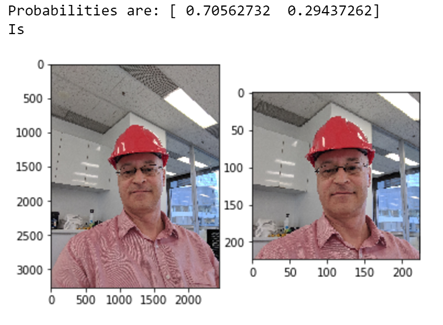
You can give the model an image it has never seen (e.g. me wearing a red safety helmet, thanks fire warden!):
4 Next
My GitHub goes onto cover how to deploy to a DeepLens (still working on that), and I’ll blog about how that works later, and what it could do if it ‘sees’ someone not wearing a safety helmet.
This example is a simple classifier (‘is’ or ‘is not’ … like the ‘Silicon Valley’ episode of ‘Hotdog not hotdog’), but could cover many different categories, or be trained to recognise people faces from a list.
The same method can be applied to numeric data (e.g. find patterns to determine if someone is likely to default on a loan), and with almost limitless cloud-based storage and processing, new applications are emerging.
I feel that the technology is already amazing enough, we can now dream up equally amazing use cases and applications for this fast moving and evolving field of deep learning!
Hi there! stunning article! I wonder when will you ever continue part 4 ^^ ? There is an object detection template that aws deeplens provides i wonder if we can use that and modify it with having custom trained models? the project creates a python green-grass deeplens function for detecting the objects but predefined with their predefined trained models that are 20 objects
check it out ^^