MuleSoft provides an extensive list of connectors which come in handy when implementing integration solutions. In many integration scenarios, we need to connect directly to a database to get or update data. MuleSoft provides a database connector which allows JDBC connectivity with relational databases to execute SQL operations such as Select, Insert, Update, Delete, and Stored Procedures.
However, the database connector only provides out-of-the-box connectivity with Oracle, MySQL, and Derby databases. To connect to Microsoft SQL Server, additional steps are to be followed. In this post I will go through the required setup and to show how to connect with a MS SQL Server database. I will implement some basic integration scenarios like querying data, updating data, and polling updated records from a SQL database.
For this post I will be using MuleSoft 3.7.2 EE and SQL Server 2014, however, you could follow the same steps to connect to other versions of SQL Server.
Pre-requisites to connect to MS SQL Server with MuleSoft.
Because MS SQL Server is not one of the supported out-of-the-box databases, the following is to be done:
- Download and install the Microsoft JDBC Drivers for SQL Server. As detailed in the Install instructions of the link, the installer is to be downloaded and run. Once run, it will prompt for installation directory, for which specifying %ProgramFiles% is suggested. For my exercise I utilised the latest version (4.2).
- Make sure TCP/IP is enabled in your SQL Server configuration as described here.
-
Add the required references to your MuleSoft project.
-
Right click on your project -> Build Path -> Add External Archives…
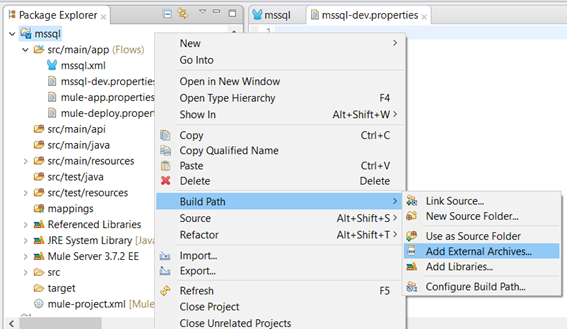
-
Select the corresponding jar file from the installation directory specified before (e.g. “C:\Program Files (x86)\Microsoft JDBC Driver 4.2 for SQL Server\sqljdbc_4.2\enu”).
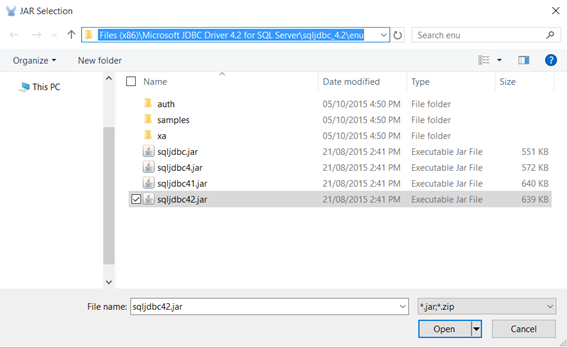
-
Validate that the library is been referenced as shown in the figure.
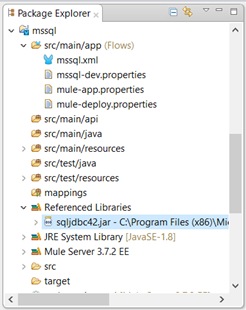
-
Now we are ready to create connections to SQL Server from AnyPoint Studio.
Create a Global Configuration Element for your SQL Server database.
Once MS SQL Server JDBC libraries are referenced by your MuleSoft project, you can create a Configuration Element to connect to a SQL Server database. For this exercise I will be using the AdventureWorks2014 Sample Database. The steps to create the global configuration element are described as follows:
- Create a new Generic Database Configuration.
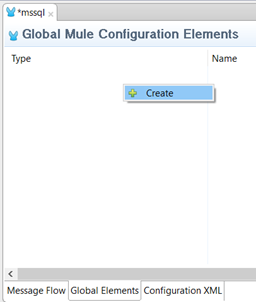
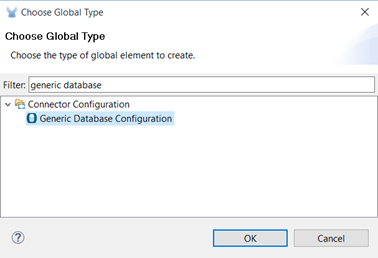
-
Set the Generic Database Configuration
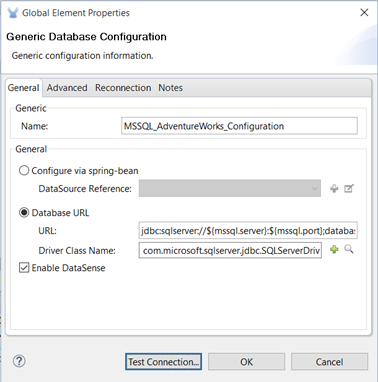
- Specify a Name.
- Specify your connection URL using the format: jdbc:sqlserver://${mssql.server}:${mssql.port};databaseName=${mssql.database};user=${mssql.user};password=${mssql.password}
- Specify the Driver Class Name as: com.microsoft.sqlserver.jdbc.SQLServerDriver
- Test connection.
The resulting XML of the Generic Database Global Configuration element should be like the one as follows:
<db:generic-config
name="MSSQL_AdventureWorks_Configuration"
url="jdbc:sqlserver://${mssql.server}:${mssql.port};databaseName=${mssql.database};user=${mssql.user};password=${mssql.password}"
driverClassName="com.microsoft.sqlserver.jdbc.SQLServerDriver"
doc:name="Generic Database Configuration"/>
Note that I am using a Property Placeholder to store my connection properties. Once the Global Configuration Element has been created, we are ready to start interacting with the database. In the following sections, I will be showing how to implement three common integration scenarios with a SQL Server database
- Querying data from a database.
- Updating data in a database.
- Polling updated records from a database.
Querying Data from a SQL Server Database
The first scenario we will go through is querying data from a SQL Server database based on a HTTP GET request. The requirement of this scenario is to get all employees from the database with first name containing a specified string. To implement this scenario, I have created the following flow containing the steps listed below:

- HTTP Listener: which expects a GET call with a query param specifying the name to search for.
- Extract Query Param: A Set Flow Variable Transformer which extracts the query param specifying the name to search for. Because I will be using a LIKE operator on my SQL query, I would default the variable to ‘%%’ to bring all available records when no filter is specified. I set the variable value as follows:
#[message.inboundProperties.‘http.query.params’.name == empty ? ‘%%’ : ‘%’ + message.inboundProperties.‘http.query.params’.name + ‘%’]
-
Get Employees from DB: Database connector to get employees matching the criterion configured as follows:
- Connector Configuration: the Generic Database Configuration Element configured previously.
- Operation: Select
-
Query Type: Parametrized
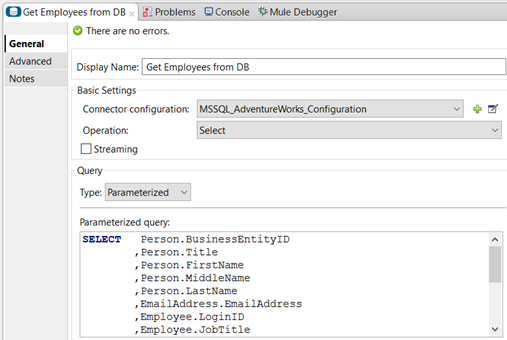
-
Parametrized query: To query employees based on the filter criterion. I will use a simple SELECT statement and will use the flow variable
#[flowVars.employeeName]
as filter as shown below:SELECT Person.BusinessEntityID
,Person.Title
,Person.FirstName
,Person.MiddleName
,Person.LastName
,EmailAddress.EmailAddress
,Employee.LoginID
,Employee.JobTitle
,Employee.BirthDate
,Employee.HireDate
,Employee.Gender
FROM Person.Person
JOIN Person.EmailAddress
ON Person.BusinessEntityID = EmailAddress.BusinessEntityID
JOIN HumanResources.Employee
ON Person.BusinessEntityID = Employee.BusinessEntityID
WHERE Person.FirstName LIKE #[flowVars.employeeName]
- Convert Object to JSON: to convert the default java.util.LinkedList
object to JSON.
At the end of the flow, the JSON payload will be returned to the caller. This is resulting configuration XML.
<http:listener-config
name="HTTP_Listener_Configuration"
host="0.0.0.0"
port="8081"
doc:name="HTTP Listener Configuration"/>
<flow name="getEmployees_Flow">
<http:listener config-ref="HTTP_Listener_Configuration"
path="/employee"
allowedMethods="GET"
doc:name="Listener GET Employees"/>
<set-variable
variableName="employeeName"
value="#[message.inboundProperties.'http.query.params'.name == empty ? '%%' : '%' + message.inboundProperties.'http.query.params'.name + '%' ]"
doc:name="Extract Query Param"/>
<db:select
config-ref="MSSQL_AdventureWorks_Configuration"
doc:name="Get Employees from DB">
<db:parameterized-query><![CDATA[
SELECT Person.BusinessEntityID
,Person.Title
,Person.FirstName
,Person.MiddleName
,Person.LastName
,EmailAddress.EmailAddress
,Employee.LoginID
,Employee.JobTitle
,Employee.BirthDate
,Employee.HireDate
,Employee.Gender
FROM Person.Person
JOIN Person.EmailAddress ON Person.BusinessEntityID = EmailAddress.BusinessEntityID
JOIN HumanResources.Employee ON Person.BusinessEntityID = Employee.BusinessEntityID
WHERE Person.FirstName LIKE #[flowVars.employeeName]
]]></db:parameterized-query>
</db:select>
<json:object-to-json-transformer
doc:name="Convert Object to JSON"/>
</flow>
Now, I should be ready to test this. I will use postman to call my endpoint.
When I call the endpoint without specifying a name using this URL http://localhost:8081/employee, I get a JSON payload with all employees.
When I call the endpoint specifying a name as a query param using this URL: http://localhost:8081/employee?name=sha, I get a JSON payload containing 3 employee records with a first name containing the string “sha”.
All good with my first scenario.
Updating Data into a SQL Server Database
In this scenario, I will update records in a database based on a HTTP PATCH request. The requirement is to update an Employee. The Employee ID is to be sent as a URI param and in the body the values to update.
To achieve this, I have created the following flow containing the steps listed below:
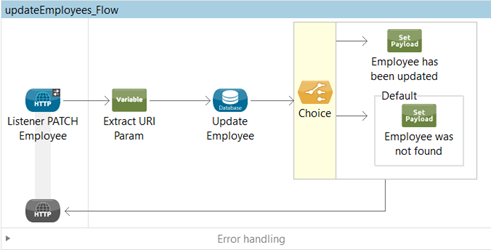
-
HTTP Listener: which expects a PATCH call with a URI param specifying the EmployeeID to update and the values to be updated specified in the body as a JSON payload. The expected payload looks like this:
{
"FirstName": "Paco",
"MiddleName": "",
"LastName": "de la Cruz",
"LoginID": "adventure-works\\paco",
"EmailAddress": paco@adventure-works.com
} - Extract URI Param: A Set Flow Variable Transformer which extracts the URI param specifying the EmployeeID to update.
-
Update Employee: Database connector to update the employee configured as follows:
- Connector Configuration: the Generic Database Configuration Element configured previously.
- Operation: Stored Procedure
- Query Type: Parametrized
-
Parametrized query (I previously created this stored procedure on the AdventureWorks2014 database):
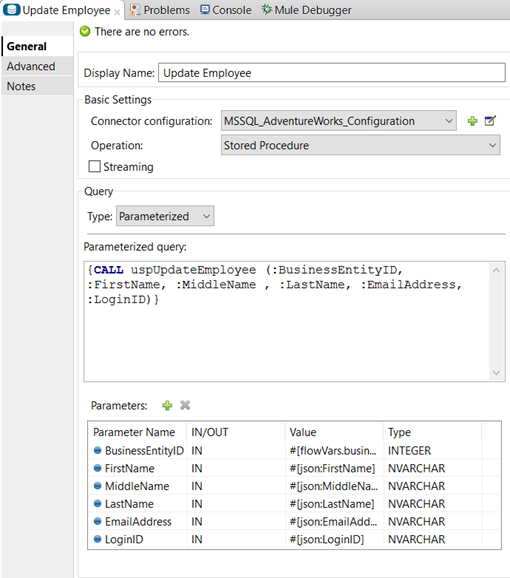
This is the syntax we have to use to call the stored procedure from MuleSoft using a parametrised query.
{CALL uspUpdateEmployee (:BusinessEntityID, :FirstName, :MiddleName , :LastName, :EmailAddress, :LoginID)}
Note the configured parameters in the picture above.
Here, it is worth mentioning that if you are using MuleSoft versions 3.7.0 or 3.7.1, you might want to update to 3.7.2 or higher to avoid this bug (Database does not supports streaming on stored procedures (java.lang.IllegalArgumentException)) when calling parametrised stored procedures.
- Choice: Return the corresponding message to the caller notifying if the employee was updated or not.
This is the resulting configuration XML.
<flow name="updateEmployees_Flow">
<http:listener
config-ref="HTTP_Listener_Configuration"
path="/employee/{id}"
allowedMethods="PATCH"
doc:name="Listener PATCH Employee"/>
<set-variable
variableName="businessEntityID"
value="#[message.inboundProperties.'http.uri.params'.id == empty ? 0 : message.inboundProperties.'http.uri.params'.id]"
doc:name="Extract URI Param"/>
<db:stored-procedure
config-ref="MSSQL_AdventureWorks_Configuration"
doc:name="Update Employee">
<db:parameterized-query>
<![CDATA[
{CALL uspUpdateEmployee (:BusinessEntityID, :FirstName, :MiddleName , :LastName, :EmailAddress, :LoginID)}
]]></db:parameterized-query>
<db:in-param
name="BusinessEntityID"
type="INTEGER"
value="#[flowVars.businessEntityID]"/>
<db:in-param
name="FirstName"
type="NVARCHAR"
value="#[json:FirstName]"/>
<db:in-param
name="MiddleName"
type="NVARCHAR"
value="#[json:MiddleName]"/>
<db:in-param
name="LastName"
type="NVARCHAR"
value="#[json:LastName]"/>
<db:in-param
name="EmailAddress"
type="NVARCHAR"
value="#[json:EmailAddress]"/>
<db:in-param
name="LoginID"
type="NVARCHAR"
value="#[json:LoginID]"/>
</db:stored-procedure>
<choice
doc:name="EmployeeUpdated?">
<when
expression="#[payload.values().toArray()[0] == 1]">
<set-payload
value="#['Employee: ' + flowVars.businessEntityID + ' has been updated.']"
doc:name="Employee has been updated"/>
</when>
<otherwise>
<set-payload
value="#['Employee: ' + flowVars.businessEntityID + ' was not found.']"
doc:name="Employee was not found"/>
</otherwise>
</choice>
</flow>
Using postman, I will test my new endpoint making a PATCH call and adding the “Content-Type” header with the value “application/json; charset=UTF-8“. I will send the payload below to update the record with EmployeeID = 1:
{
"FirstName": "Paco",
"MiddleName": "",
"LastName": "de la Cruz",
"LoginID": "adventure-works\\paco",
"EmailAddress": "paco@adventure-works.com"
}
When I call the endpoint using this URL http://localhost:8081/employee/1, I get the message that the record has been updated. When I check the database, I am now the new CEO of Adventure Works .
When I call the endpoint using this URL http://localhost:8081/employee/0, I get the message that the Employee was not found.
All done with this scenario.
Polling updated records from a SQL Server Database
The last integration scenario is very common, particularly when implementing the Pub-Sub pattern, in which changes in a source system have to be published to one or more subscribers. The good news is that MuleSoft provides polling updates using watermarks, which comes in very handy and easy to implement. Below I explain how to do this with a SQL database.
I created the following flow with the steps listed below to implement the polling scenario.
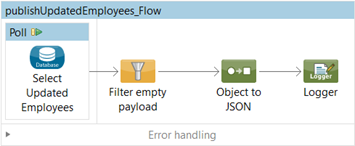
-
Poll Scope: The poll scope requires to change the Processing Strategy of the flow to: “synchronous”
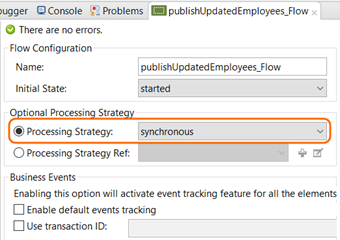
The polling scope won’t work if you leave the default processing strategy, which is asynchronous. If you got the error below, you know then what to do .
Message : Watermarking requires synchronous polling
Code : MULE_ERROR-344
For this scenario I configured the polling to occur once a day. To get only updated records, I am implementing watermarking utilising the ModifiedDate in the payload as shown below.
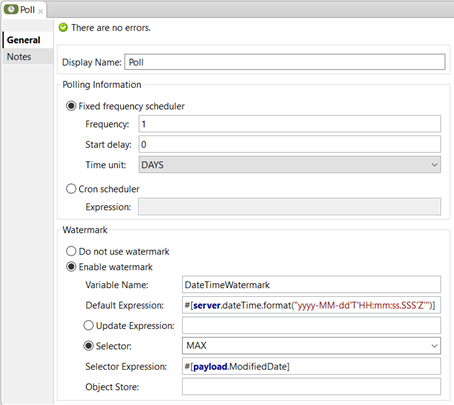
-
Select Updated Records: Inside the Poll scope, I implemented a database connector to select the updated records as shown in the figure. To get only the updated records, I am filtering those which the ModifiedDate is greater (later) than the flow variable DateTimeWatermark, the watermark created on the Poll scope.
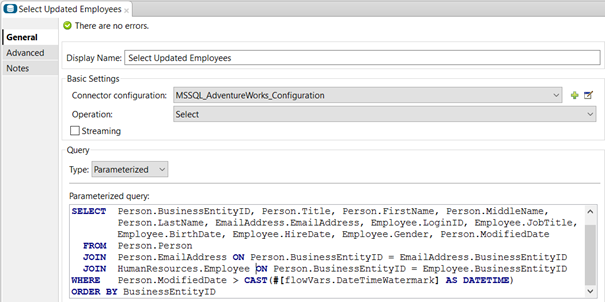
-
Filter empty payload: To stop the flow when no updated records are obtained, using the following expression:
#[payload.size() > 0]
- Convert Object to JSON: to get a JSON payload out of the result set.
- Logger: just as a way to test the flow.
This is resulting configuration XML.
<flow name="publishUpdatedEmployees_Flow"
initialState="started"
processingStrategy="synchronous">
<poll
doc:name="Poll">
<fixed-frequency-scheduler
frequency="1"
timeUnit="DAYS"/>
<watermark
variable="DateTimeWatermark"
default-expression="#[server.dateTime.format("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'")]"
selector="MAX"
selector-expression="#[payload.ModifiedDate]"/>
<db:select
config-ref="MSSQL_AdventureWorks_Configuration"
doc:name="Select Updated Employees">
<db:parameterized-query><![CDATA[
SELECT Person.BusinessEntityID
,Person.Title
,Person.FirstName
,Person.MiddleName
,Person.LastName
,EmailAddress.EmailAddress
,Employee.LoginID
,Employee.JobTitle
,Employee.BirthDate
,Employee.HireDate
,Employee.Gender
,Person.ModifiedDate
FROM Person.Person
JOIN Person.EmailAddress
ON Person.BusinessEntityID = EmailAddress.BusinessEntityID
JOIN HumanResources.Employee
ON Person.BusinessEntityID = Employee.BusinessEntityID
WHERE Person.ModifiedDate > CAST(#[flowVars.DateTimeWatermark] AS DATETIME)
ORDER BY BusinessEntityID
]]></db:parameterized-query>
</db:select>
</poll>
<expression-filter
expression="#[payload.size() >0]"
doc:name="Filter empty payload"/>
<json:object-to-json-transformer
doc:name="Object to JSON"/>
<logger
level="INFO"
doc:name="Logger"
message="#[payload]"/>
</flow>
To test this scenario, I called the API to update data on my SQL database previously implemented (PATCH request to http://localhost:8081/employee/{id}) with different IDs, so different employees were updated. Then, I ran my solution and the polling started getting only the updated records. As simple and beautiful as that!
In this post I have shown you how to prepare your environment and your MuleSoft AnyPoint studio to work with Microsoft SQL Server, how to create a Global Configuration Element for a SQL database, how to search and poll changes from a SQL database, and how to update records as well. I hope now you have a better idea of how to connect to a MS SQL Server from your MuleSoft solutions. Thanks for reading!
Thanks for writing the article!
As a beginner to mulesoft, I find it extremely informative.
I am trying to get data from SQl server database. I am able to connect to database but i am not able to the see “object to json” connector in mule4. Any help how do i return data to json from “select” connector.
Thanks for your comment Dan.SG, good luck with your journey with MuleSoft!
Hi, Where to specify the environment variable values in the database url “jdbc:sqlserver://${mssql.server}:${mssql.port};databaseName=${mssql.database};user=${mssql.user};password=${mssql.password}”. I get error bad connectionstring I am using Advanced tab Advanced Parameters to specify values.
Thank you.
Hi Venkatesh,
This link provides details on how to create and use environment variables
https://docs.mulesoft.com/mule-user-guide/v/3.8/deploying-to-multiple-environments
So far, I’ve only done the connection part and it works perfectly. I’ve spent the whole day trying to get this done and thanks to you now I did it. Thanks Paco, I owe you my life jajajaja.
I am glad you’ve found this post useful 🙂 Keep having fun with MuleSoft!
Very helpful Paco! I added the external archive but was getting an error after deploying (both run and debug in Anypoint studio): org.mule.module.db.internal.domain.connection.ConnectionCreationException: java.sql.SQLException: Error trying to load driver: com.microsoft.sqlserver.jdbc.SQLServerDriver : Cannot load class ‘com.microsoft.sqlserver.jdbc.SQLServerDriver’ (java.sql.SQLException) (org.mule.module.db.internal.processor.DbConnectionException).
I then found this article which recommends putting the .jar into specific path under Anypoint studio. Once I did that it loaded properly. Perhaps this is MuleSoft best practice I don’t know.
https://support.mulesoft.com/s/article/Loading-the-Database-Connector-JDBC-Driver-in-Studio-Runtime
Again thanks for the post Paco. Everything running great now.
Hi Matt, I’m glad you found the post helpful. And thanks for sharing your findings. Happy coding 🙂
Reblogged this on Sprouting Bits and commented:
Reblogging this post to my personal archive 🙂
what is d format for connecting db2 like “jdbc:db2://172.17.0.142:50001/itgdb”, “mssusr21″,”miracle21”
Hi Paco,
This is really helpful for me. I’m a novice to Mulesoft.
Hi I need to connect Access DB and need query some data how can I proceed. Please help me this. In this post all about connecting to MS SQL server. My requirement is to connect Access DB.
thanks in advance.